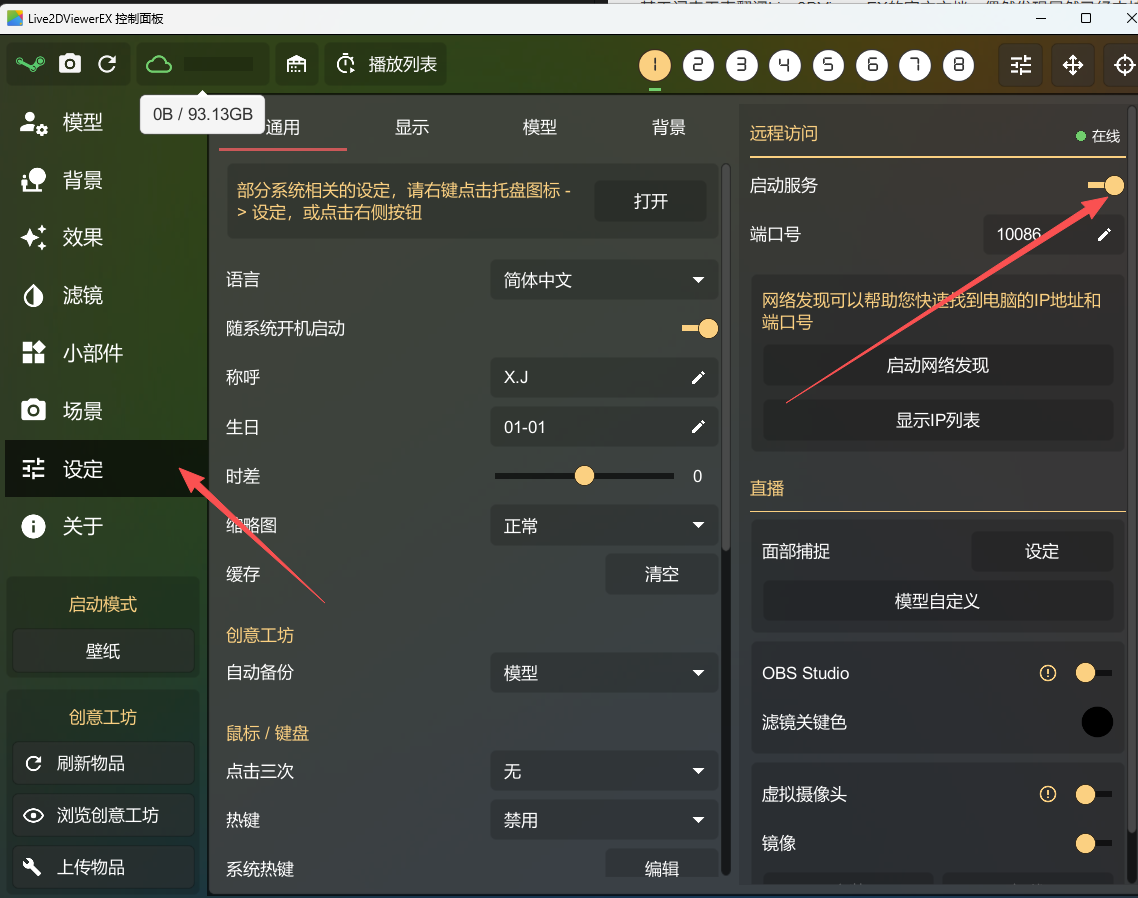
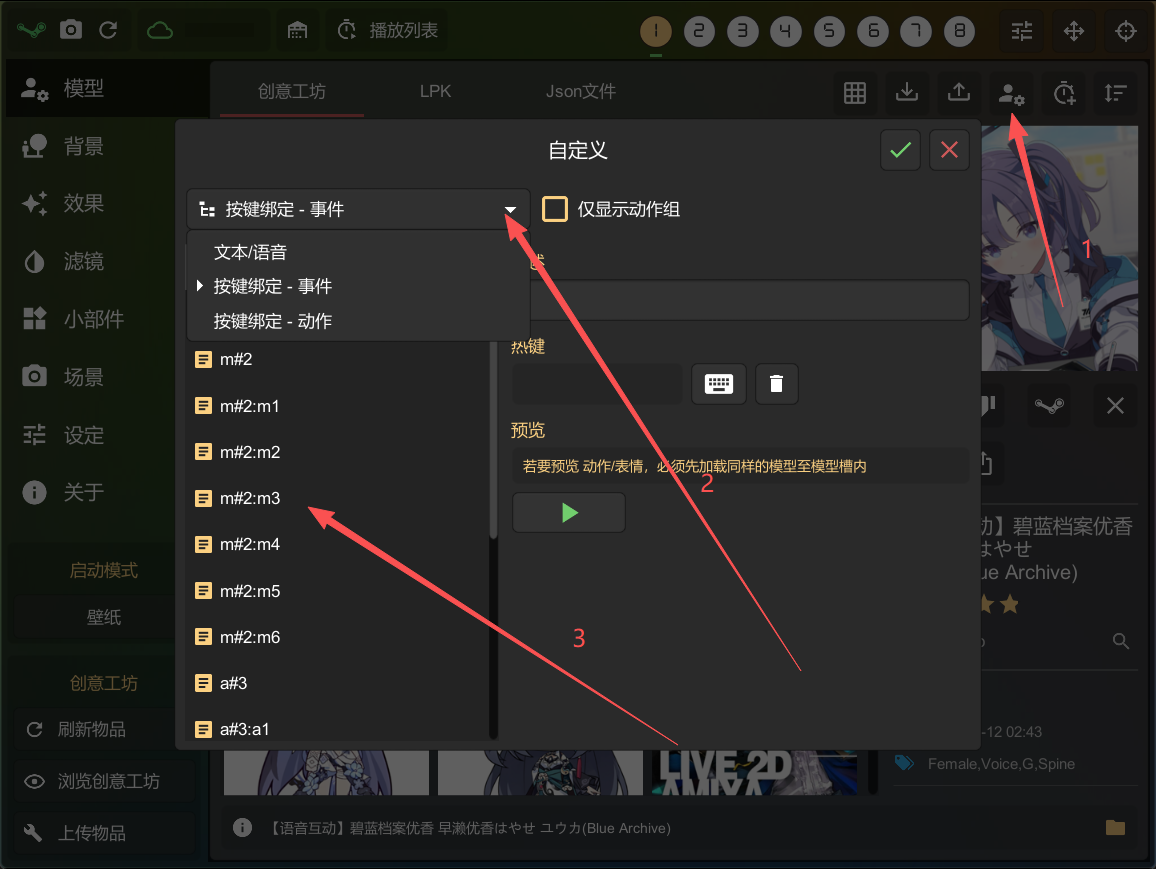
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
| import json
import os
import requests
from websocket import create_connection
from openai import OpenAI
import time
import threading
import imapclient
import pyzmail
from datetime import date
file_path = "prompt.txt"
try:
with open(file_path, "r", encoding="utf-8") as file:
system_prompt = file.read()
except FileNotFoundError:
print(f"错误:文件 {file_path} 未找到。")
except Exception as e:
print(f"读取文件时发生错误:{e}")
client = OpenAI(
api_key="sk-xxxxxxxxxxxxx",
base_url="https://api.moonshot.cn/v1",
)
TTS_API_URL = "http://127.0.0.1:9880/tts"
REF_AUDIO_PATH = "C:\\Users\\X.J\\Desktop\\GPT-SoVITS-1007-cu124\\1.ogg"
PROMPT_TEXT = "衝動買いは禁止!消費はちゃんと計画的にっ!"
PROMPT_LANG = "ja"
TEXT_LANG = "zh"
system_messages = [
{"role": "system", "content": system_prompt},
]
messages = []
def make_new_messages(input: str , n: int = 10) -> list[dict]:
global messages
messages.append({
"role": "user",
"content": input
})
new_messages = []
new_messages.extend(system_messages)
if len(messages) > n:
messages = messages[-n:]
new_messages.extend(messages)
return new_messages
def get_tts_audio(text: str, output_file: str = "output.wav") -> bool:
"""
调用TTS API的GET方法生成音频并保存
:param text: 待合成的文本
:param output_file: 音频输出路径
:return: 成功返回True,失败返回False
"""
params = {
"text": text,
"text_lang": TEXT_LANG,
"ref_audio_path": REF_AUDIO_PATH,
"prompt_lang": PROMPT_LANG,
"prompt_text": PROMPT_TEXT,
"text_split_method": "cut2",
"batch_size": 1,
"media_type": "wav",
"streaming_mode": False
}
try:
response = requests.get("http://127.0.0.1:9880/tts", params=params)
if response.status_code == 200:
with open(output_file, "wb") as f:
f.write(response.content)
print(f"音频已保存至:{output_file}")
return True
else:
print(f"TTS API调用失败:{response.json().get('message', '未知错误')}")
return False
except Exception as e:
print(f"调用TTS API时发生错误:{str(e)}")
return False
def send_json_message(json_message: str):
uri = "ws://127.0.0.1:10086/api"
data = {
"msg": 11000,
"msgId": 1,
"data": {
"id": 0,
"text": json_message,
"textFrameColor": 0x000000,
"textColor": 0xFFFFFF,
"duration": 30000
}
}
try:
ws = create_connection(uri)
ws.send(json.dumps(data))
except Exception as e:
print("错误:", str(e))
def send_expression():
uri = "ws://127.0.0.1:10086/api"
data = {
"msg": 13200,
"msgId": 1,
"data": {
"id": 0,
"type": 0,
"mtn": "a#3:a3"
}
}
try:
ws = create_connection(uri)
ws.send(json.dumps(data))
except Exception as e:
print("错误:", str(e))
def send_sound():
uri = "ws://127.0.0.1:10086/api"
data ={
"msg": 13500,
"msgId": 1,
"data": {
"id": 0,
"channel":0,
"volume":1,
"delay":0,
"type":0,
"sound":"C:\\Users\\X.J\\Desktop\\live2d_ai\\output.wav"
}
}
try:
ws = create_connection(uri)
ws.send(json.dumps(data))
except Exception as e:
print("错误:", str(e))
def chat(input: str) -> str:
completion = client.chat.completions.create(
model="moonshot-v1-8k",
messages=make_new_messages(input),
temperature=0.3,
)
mita_message = completion.choices[0].message.content
messages.append({
"role": "assistant",
"content": mita_message
})
get_tts_audio(mita_message)
return mita_message
PROCESSED_UIDS = set()
def get_data():
global PROCESSED_UIDS
imap_object = imapclient.IMAPClient('imap.qq.com', ssl=True)
imap_object.login('xxxxxx@qq.com', '[你的16位码]')
imap_object.select_folder('INBOX', readonly=False)
since_date = date.today().strftime('%d-%b-%Y')
UIDs = imap_object.search(['SINCE', since_date, 'UNSEEN'])
new_UIDs = [uid for uid in UIDs if uid not in PROCESSED_UIDS]
if not new_UIDs:
print("[INFO] 暂无新邮件。")
else:
print(f"[INFO] 检测到 {len(new_UIDs)} 封新邮件:")
for i in new_UIDs:
str_ = "老师,有新的邮件发来。"
raw_message = imap_object.fetch(i, ['BODY[]'])
message_object = pyzmail.PyzMessage.factory(raw_message[i][b'BODY[]'])
subject = message_object.get_subject()
from_addr = message_object.get_addresses('from')
print(f"---\n主题: {subject}\n发件人: {from_addr[0][0]}")
str_ += "主题:"+subject+ ",发件人是:"+ str(from_addr[0][0])
if message_object.text_part:
text = message_object.text_part.get_payload().decode(message_object.text_part.charset)
print(f"文本内容: {text[:100]}...")
str_ += "。文本内容是:"+text[:100]
elif message_object.html_part:
html = message_object.html_part.get_payload().decode(message_object.html_part.charset)
print(f"HTML内容: {html[:100]}...")
else:
print("无正文内容")
str_ += "无正文内容"
imap_object.add_flags(i, [b'\\Seen'])
PROCESSED_UIDS.add(i)
get_tts_audio(str_)
send_sound()
send_json_message(str_)
imap_object.logout()
def listen_email():
while True:
get_data()
time.sleep(1)
if __name__ == '__main__':
listener_thread = threading.Thread(target=listen_email, daemon=True)
listener_thread.start()
print('[INFO] 邮件监听线程已启动,主循环开始。')
while True:
try:
saying = input("Player:")
if saying == "exit loop":
break
response = chat(saying)
send_json_message(response)
send_sound()
print(response)
except Exception as e:
print(f"大模型出现错误:{e}")
|