GPT-SoVITS的本地部署与使用
GPT-SoVITS的本地部署与使用,支持本地调试和本地接口调用
前言
对GPT-SoVITS的学习也是早有预谋了,起因是前面的一个Blog对应Demo需要的模块,通过用户输入返回给文本AI响应,并发送给TTS生成音频,且音频音色要与对应的Live2D角色相近。。。
欸!这不是能给我们的《数据分析与可视化实践》课程的speech_agent替掉吗?
先列出学习过程中的参考:
官方教程文档
安装
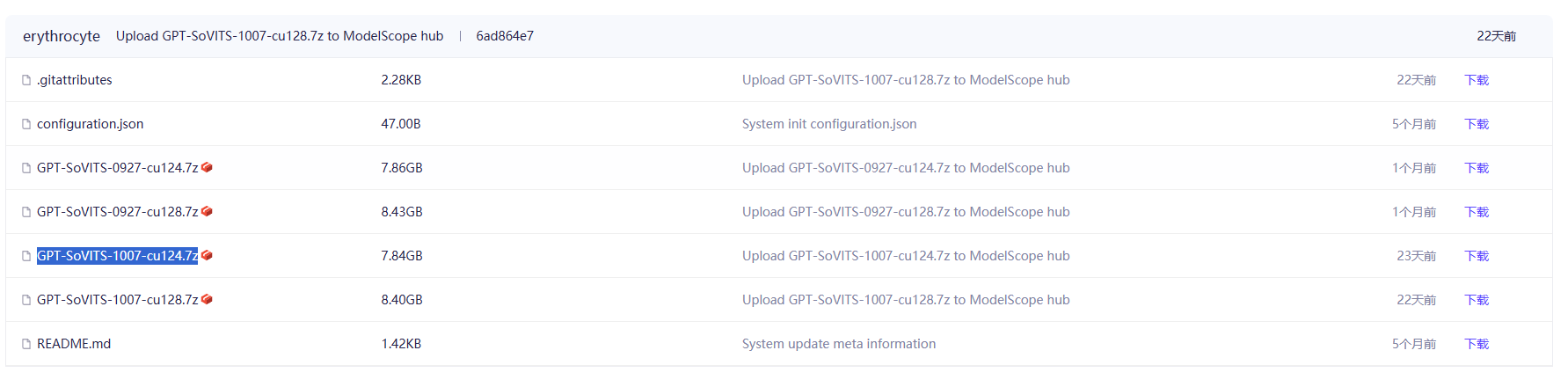
在上面的文件中,后缀为cu128是适配N卡50系以上的包,由于我们不是50系显卡,选择cu124
我这里选择了GPT-SoVITS-1007-cu124.7z。
下载后正常解压即可
模型的下载
为了连贯性,写在使用说明前面。
模型是什么: 模型是TTS的灵魂本身,即生成的声音的 音色来源,你想听到什么样的声音就去找什么样的模型。当然以我们本地的算力是不支持训练模型的,所以我们的选择是在各大论坛和技术交流网站寻找合适的模型。
模型的版本是什么: 目前的模型分为v1,v2,v2pro,v2proplus,v4的版本,可以在GPT-SoVITS使用对应的版本进行生成。
模型下载资源(由于GPT-SoVITS的用途,模型大多都是二次元相关的):
官方文档提供的模型分享社区 : https://www.ai-hobbyist.com
几位大佬自己训练的模型 : https://pan.baicai1145.com/baicai1145/GPT-SOVITS%E6%A8%A1%E5%9E%8B/V4
太有互联网精神了😭
模型下载并解压,以v4版本的模型为例,将 .pth 后缀的文件放在项目文件夹下的 SoVITS_weights_v4 下, 将 .ckpt 后缀的文件放在项目文件夹下的 GPT_weights_v4 下。
注意 :下载的是什么版本的模型就放在对应的 _vxxx 的文件夹下
下载后的模型文件夹下如果有一些 模型作者留下的音频文件 ,记得保留,后面会用到。
进入TTS推理WebUI
作者提供了WebUI的使用和Api调用两种方法,我们先从图形化界面的使用开始,并捎带一些简单的基础知识。
双击根目录下的 go-webui.bat 文件,稍加等待,cmd会在加载完成后跳转至运行的图形化界面(网页),默认url: http://0.0.0.0:9874
界面如下:
由于我们是直接下载别人的模型使用,依次点击 1-GPT-SoVIRS-TTS 1C-推理 开启TTS推理WebUI
随后稍等片刻,等待新页面弹出。
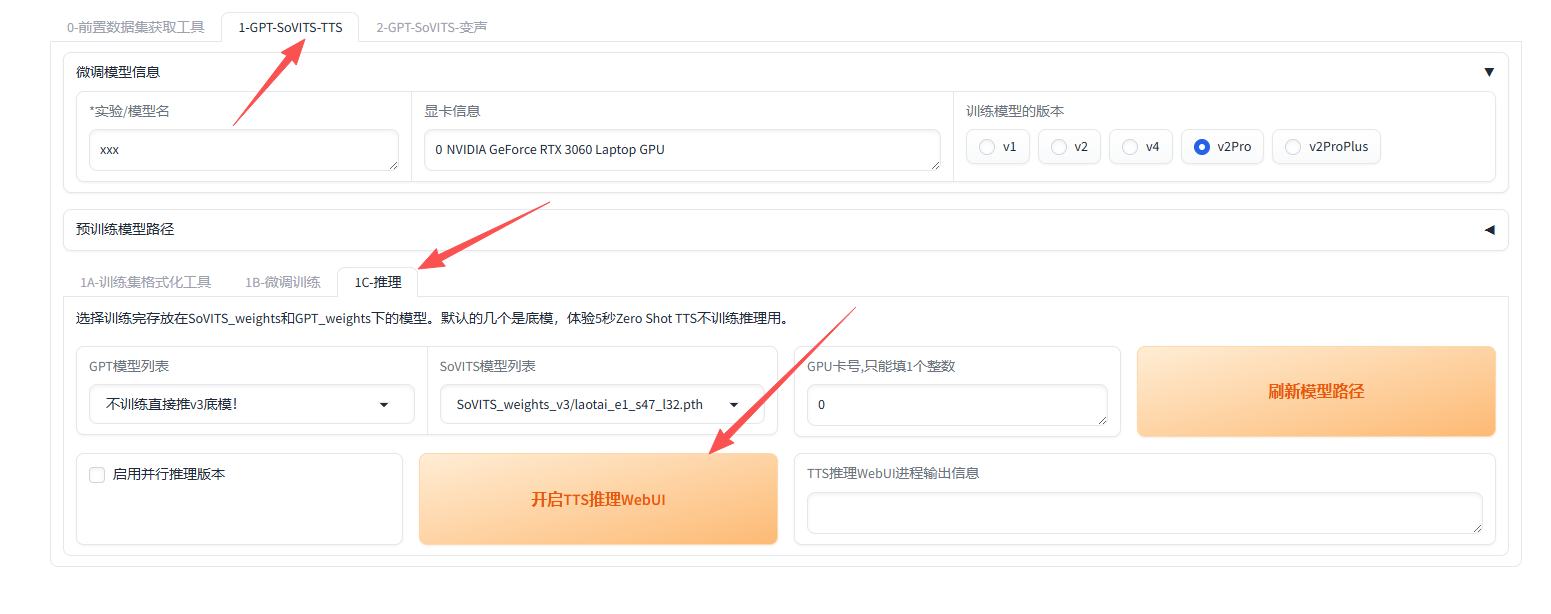
随后进入了新页面
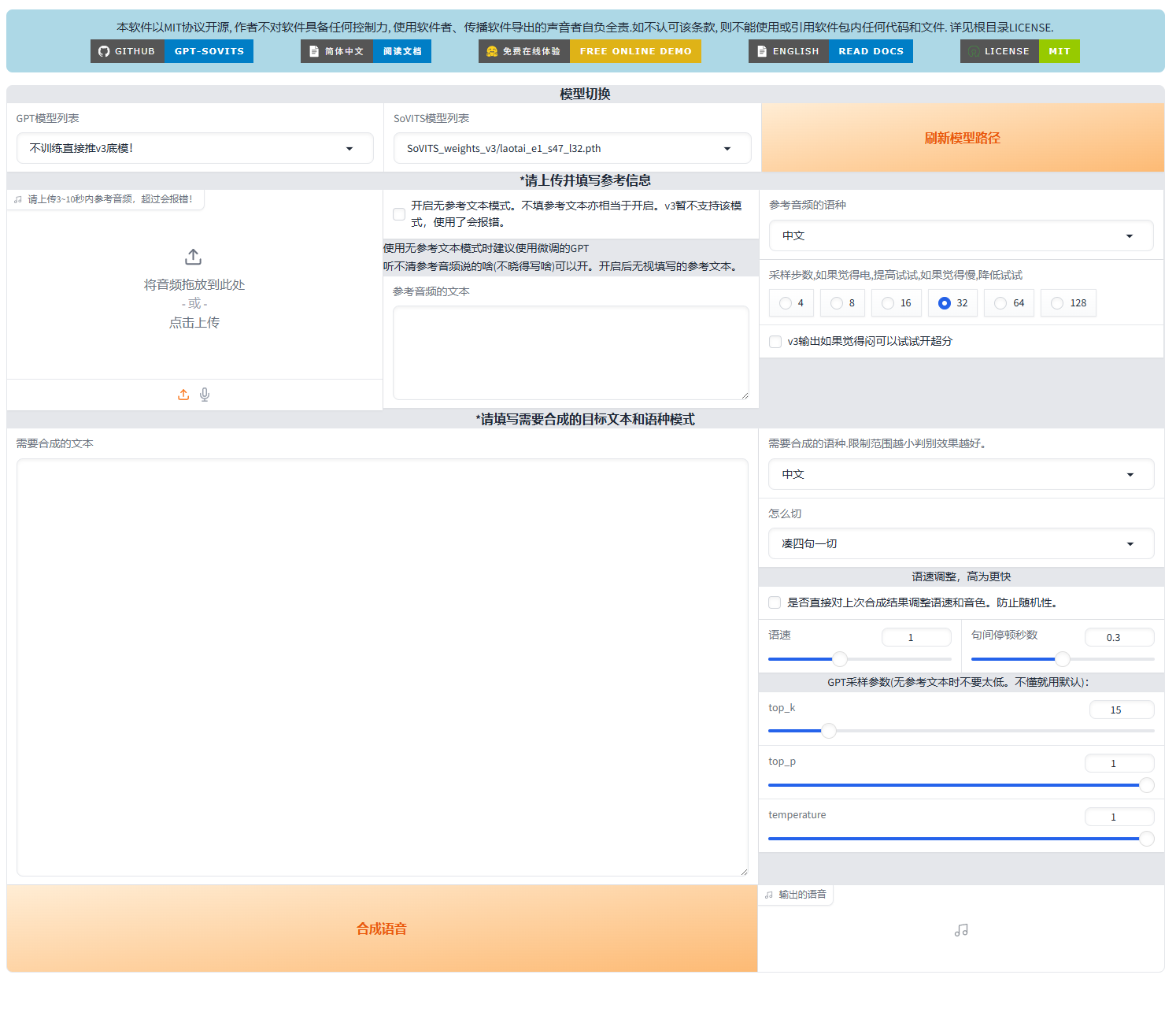
使用TTS推理WebUI
GPT模型列表和SoVITS模型列表
分别选择之前我们放在对应文件夹下的模型即可
请上传3-10秒内参考音频 与 参考音频的文本
选择模型文件夹下作者附带的参考音频即可,参考音频的文本输入对应音频内容的文本即可(一般也会随模型附带)
模型本身的文件决定了它的音色,这两项的作用是确定接下来模型的语调。所以在自己训练模型使用时也可以根据要生成的语音,选择对应的参考音频,从而展现出生成音频的带有情绪化的语调。
参考音频的语种 与 需要合成的文本 与 需要合成的语种
顾名思义,要生成什么填什么。
在此提醒,最好使用对应语言训练的模型输出对应的语言,如果强迫让日文模型说中文会有一股丁真的风味,同样中文模型说英文也会有Chinglish的味道。 正如前面所说,训练模型时留下的音色决定了上面的不同,不同的语言的不同发音习惯导致了这一点。
剩下的一些参数
不懂就别乱调,因为我也不懂
最终示例
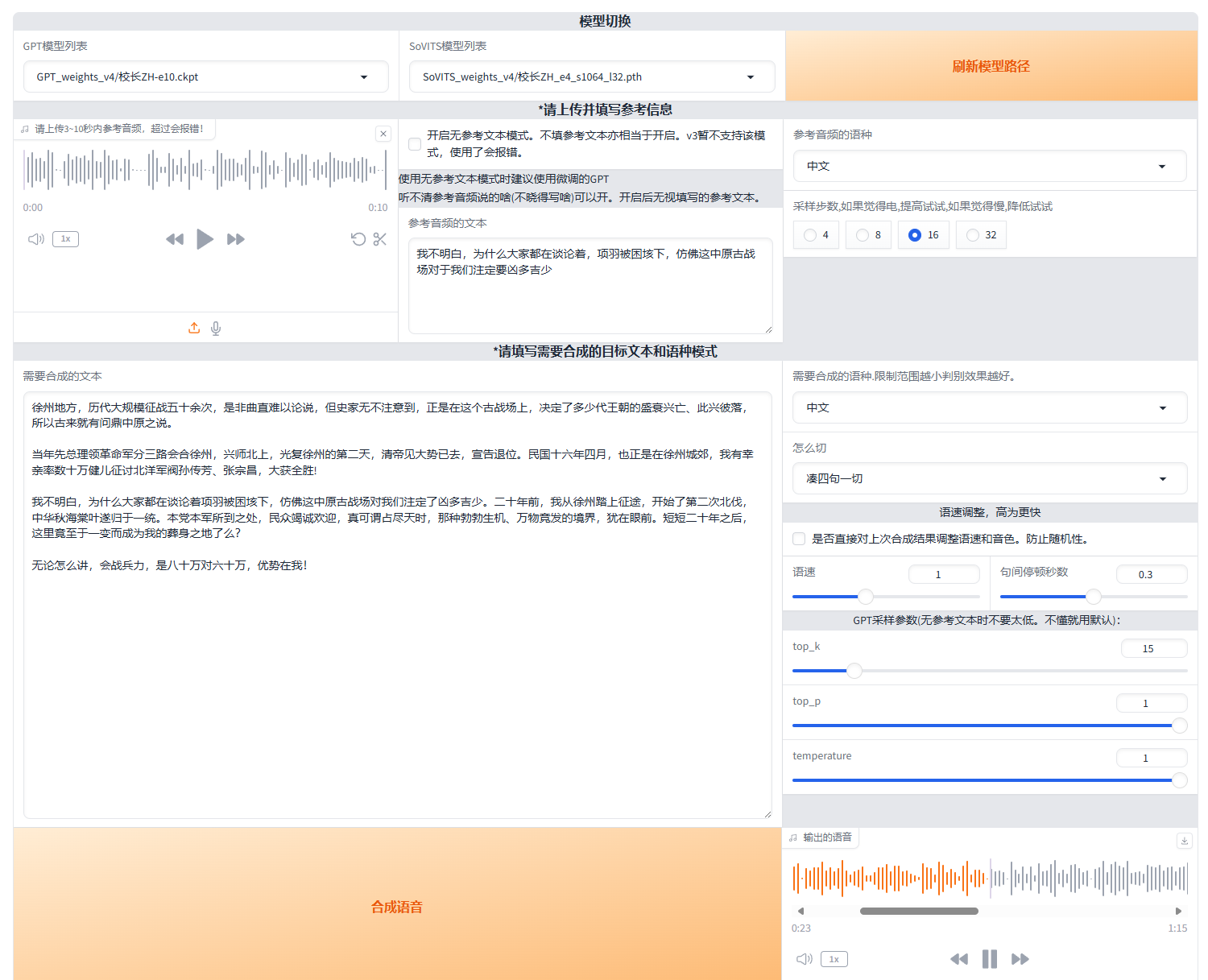
接口调用
那么如何使用接口去调用GPT-SoVITS呢?
所幸,作者考虑了这一点,为我们留下了宝贵的财富——根目录下的 api_v2.py
修改bat 并启动api服务
方便起见,我们仍然使用bat启动程序。
在根目录下新建文件 api.bat
记事本打开,输入
1 | set "SCRIPT_DIR=%~dp0" |
保存并退出,随后双击 api.bat 即可启动项目的api端口
随后观察cmd(现在是运行py的状态,没有图形化界面了,cmd的输出至关重要)
1 | C:\Users\X.J\Desktop\GPT-SoVITS-1007-cu124>runtime\python.exe -I api_v2.py |
会自动读取你的模型
来自路径 GPT-SoVITS-1007-cu124\GPT_SoVITS\configs\tts_infer.yaml
修改其中的模型路径以及版本即可。
1 | custom: |
随后再观察
1 | INFO: Started server process [26560] |
证明api服务启动成功
观察接口
浏览器输入 http://127.0.0.1:9880/docs ,即可进入项目的fastapi界面,其中我们主要使用的只有一个接口 /tts
观察接口需要的参数:
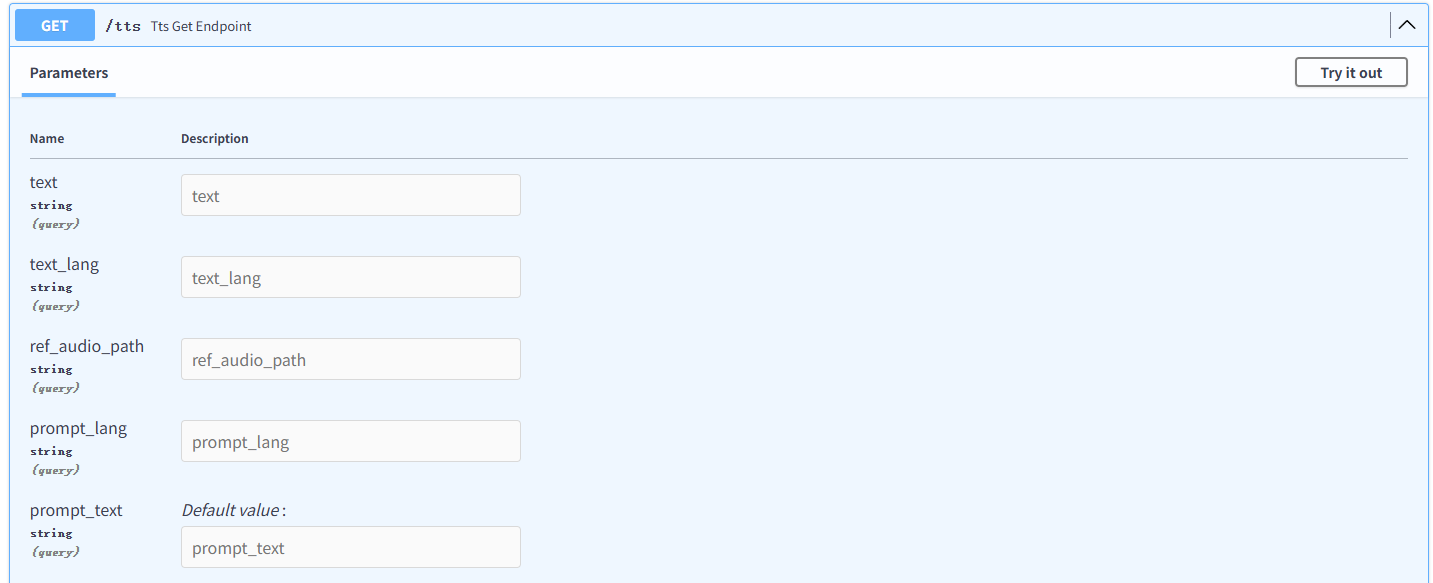
其中 text 与 text_lang 为需要生成的文本和语言
注意: text_lang为英文缩写,ch ja en 等
ref_audio_path 为参考音频的路径
prompt_text 与 prompt_lang 为参考音频的文本和语言
调用接口
1 | def get_tts_audio(text: str, output_file: str = "output.wav") -> bool: |
调用接口后可以观察cmd输出,会有一个小进度条,完成后音频则输出在指定位置。