使用selenium写一个简单的智慧树刷课脚本
前言
《软件测试技术》Lab3教了Selenium的Java使用,虽然我很清楚这个东西大概率是要我们配合Junit测试JavaWeb的,但是。。。这玩意拿来写python整两个脚本不也不错吗?!
简单使用
首先附上官方文档,非常详尽的文档而还是中文!
https://www.selenium.dev/zh-cn/documentation/
最简单的实例
1
2
3
4
5
6
7
| from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://selenium.dev")
driver.quit()
|
欸?怎么网页刚打开就关上了?
time.sleep(5)一下就是喽,在Selenium的使用中time.sleep是非常常用的。
元素定位器
| 定位器 Locator |
描述 |
| class name |
定位class属性与搜索值匹配的元素(不允许使用复合类名) |
| css selector |
定位 CSS 选择器匹配的元素 |
| id |
定位 id 属性与搜索值匹配的元素 |
| name |
定位 name 属性与搜索值匹配的元素 |
| link text |
定位link text可视文本与搜索值完全匹配的锚元素 |
| partial link text |
定位link text可视文本部分与搜索值部分匹配的锚点元素。如果匹配多个元素,则只选择第一个元素。 |
| tag name |
定位标签名称与搜索值匹配的元素 |
| xpath |
定位与 XPath 表达式匹配的元素 |
熟悉Javascript的应该不会陌生,就是那个getElementById()、getElementByName()……
熟悉QT的应该也不会陌生,就是那个ui->pushButton
总之,元素定位器的作用就是定位HTML中的元素,拿到对应的元素对象
类型为WebElement,话说python也没必要说类型什么的
举个例子
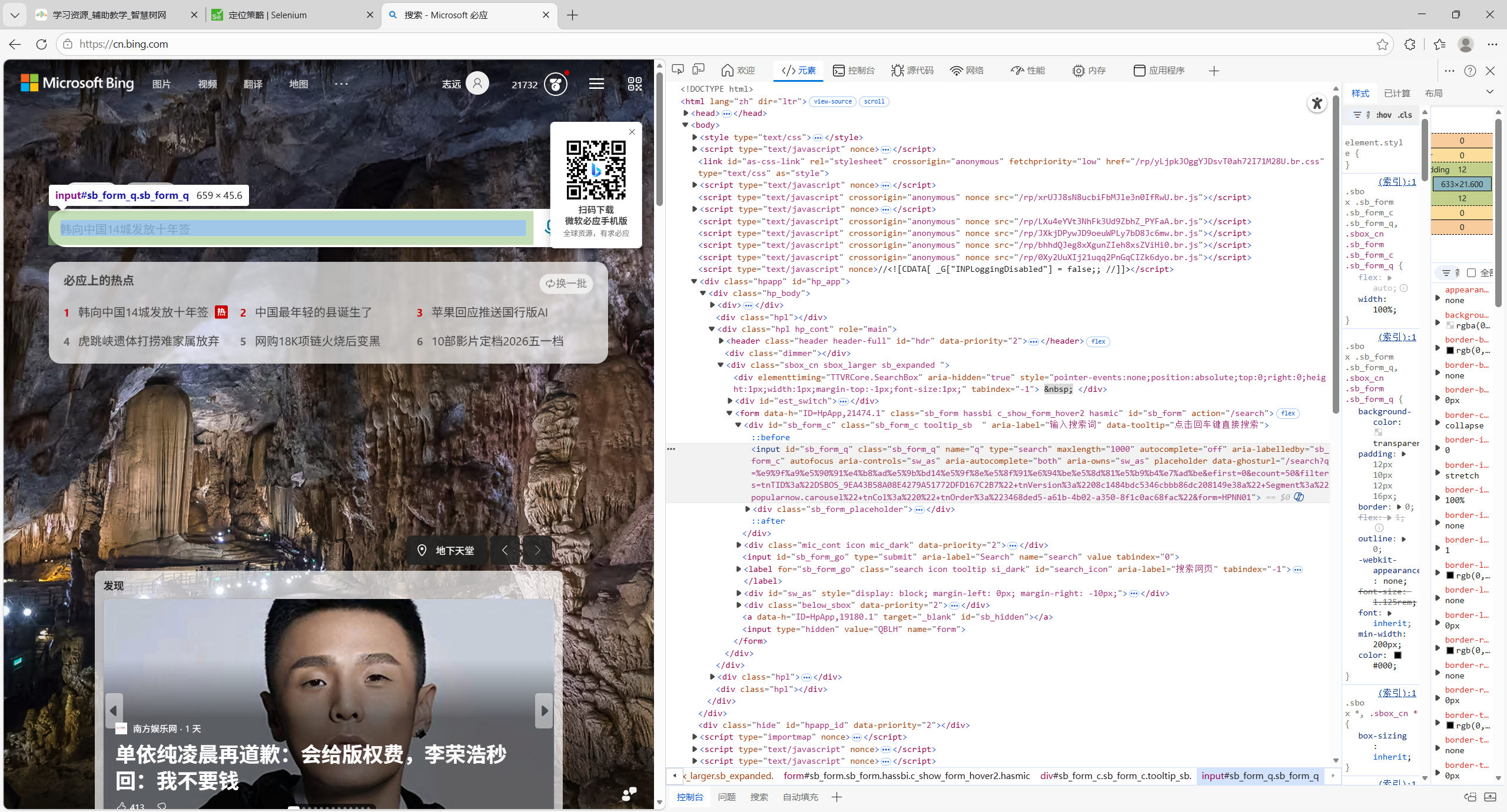
在https://cn.bing.com/中,右键搜索框“检查”,即可进入开发者模式查看对应元素的HTML
1
| <input id="sb_form_q" class="sb_form_q" name="q" type="search" maxlength="1000" autocomplete="off" aria-labelledby="sb_form_c" autofocus="" aria-controls="sw_as" aria-autocomplete="both" aria-owns="sw_as" placeholder="" data-ghosturl="/search?q=%e9%9f%a9%e5%90%91%e4%b8%ad%e5%9b%bd14%e5%9f%8e%e5%8f%91%e6%94%be%e5%8d%81%e5%b9%b4%e7%ad%be&efirst=0&ecount=50&filters=tnTID%3a%22DSBOS_9EA43B58A08E4279A51772DFD167C2B7%22+tnVersion%3a%2208c1484bdc5346cbbb86dc208149e38a%22+Segment%3a%22popularnow.carousel%22+tnCol%3a%220%22+tnOrder%3a%223468ded5-a61b-4b02-a350-8f1c0ac68fac%22&form=HPNN01">
|
在这里,搜索框的id为sb_form_q,即可写
1
| search_box = driver.find_element(By.id,"sb_form_q")
|
那有人要问了,为什么class=”sb_form_q”,为什么不用class搜呢?写过HTML+CSS都知道,相同UI样式的元素class会写成一样的,尽管在此处搜索框的确是唯一的,但是这种明确指向一个元素的还是不要用Class的好。
其中,第一项driver为我们最开始网页,可以理解为driver是整体HTML,得到的search_box是部分HTML,所以find_element的结果也可以在下一次作为find_element的被find的主体。
再举例,bing中的搜索按钮,同理
1
| <label for="sb_form_go" class="search icon tooltip si_dark" id="search_icon" aria-label="搜索网页" tabindex="-1"><svg viewBox="0 0 25 25"><path class=" " stroke="#007DAA" stroke-width="2.5" stroke-linecap="round" stroke-miterlimit="10" fill="none" d="M23.75 23.75l-9-9"></path><circle class=" " stroke="#007DAA" stroke-width="2.5" stroke-linecap="round" stroke-miterlimit="10" cx="9" cy="9" r="7.75" fill="none"></circle><path fill="none" d="M25 25h-25v-25h25z"></path></svg></label>
|
id为search_icon,即可写
1
| search_bt = driver.find_element(By.id,"search_icon")
|
Web元素交互
得到了Web元素之后,显然下一步就是交互了。即JS与QT喜闻乐见的xxx.setText()、xxx.click()
Selenium的几种交互都较为简单
点击
xxx.click()
输入文本
xxx.send_keys(“123abc”)
清除文本
xxx.clear()
那么接着上面的例子,我们在元素获取阶段获得了搜索框和搜索按钮两个元素,接下来我们实现输入搜索内容并点击搜索的流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://selenium.dev")
search_box = driver.find_element(By.id,"sb_form_q")
search_bt = driver.find_element(By.id,"search_icon")
search_box.send_keys("Selenium")
time.sleep(5)
search_bt.click()
driver.quit()
|
实战
要完成的是智慧树的自动刷课脚本。
实现逻辑
我们平时正常的智慧树刷课逻辑是什么?
点击智慧树官网->登录->进入对应课程->选择进度为未完成的课程->点击播放键->等待放完->……
因此我们也可以为此模拟出一套Selenium的刷课逻辑:
进入智慧树官网->填写用户名密码并按登录按钮->通过url跳转到要刷的课程->获取所有未完成的视频->While True循环播放所有视频
进入智慧树官网
注意,我们使用selenium是新开的页面,不会保留登陆状态,因此每次都要重新登陆,所以最开始访问什么url并不重要,因为智慧树设定为从任何url进入登陆页面,登陆成功之后不会到达对应页面。。。
1
2
3
| driver = webdriver.Edge()
driver.get("https://wenda.zhihuishu.com/stu/courseInfo/studyResource?courseId=11505944")
|
填写用户名密码并按登录按钮
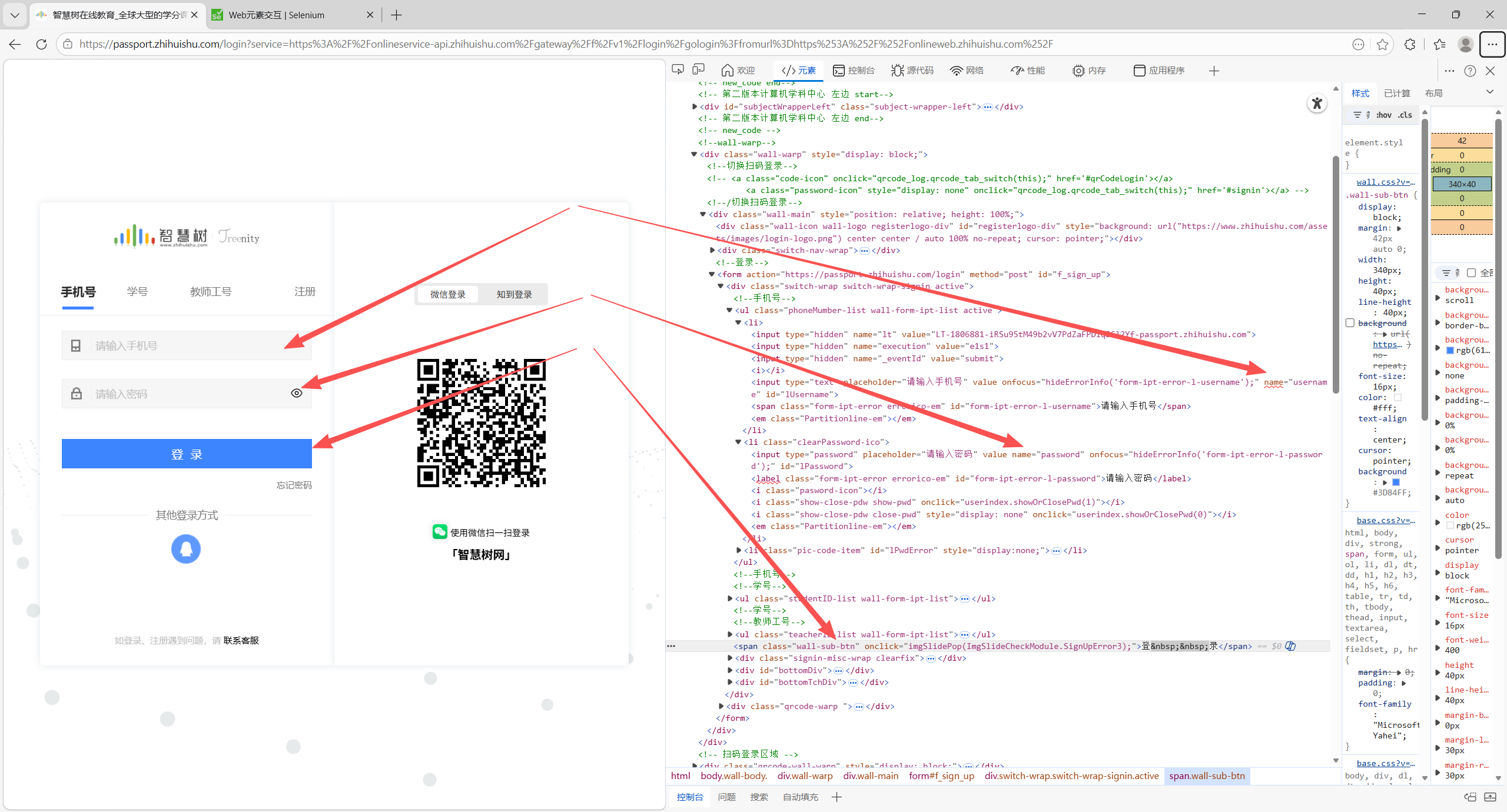
要找到的元素有三:用户名输入框,密码输入框,登录按钮
1
2
3
4
5
6
7
8
9
10
| driver.find_element(By.NAME,"username").send_keys("yourUsername")
driver.find_element(By.NAME,"password").send_keys("yourPassWord")
driver.find_element(By.CSS_SELECTOR,"span.wall-sub-btn").click()
while True:
if driver.title == "智慧树在线教育_全球大型的学分课程运营服务平台":
time.sleep(1)
print("轮询等待用户验证")
else :
break
|
click之后你会发现,还有个滑块验证框,这个该怎么办呢?
这个属于CV领域,可以使用相关办法破解,在这里我们就不做这个了。
通过url跳转到要刷的课程
1
2
3
| driver.get(f"https://wenda.zhihuishu.com/stu/courseInfo/studyResource?courseId={courseId}")
time.sleep(5)
|
记得sleep一会
获取所有未完成的视频
在智慧树的课程目录下,我们要刷的是视频资源,这个直接筛掉不是”mp4”的即可。
至于如何在获取所有视频时判断是否是“已完成”的状态:
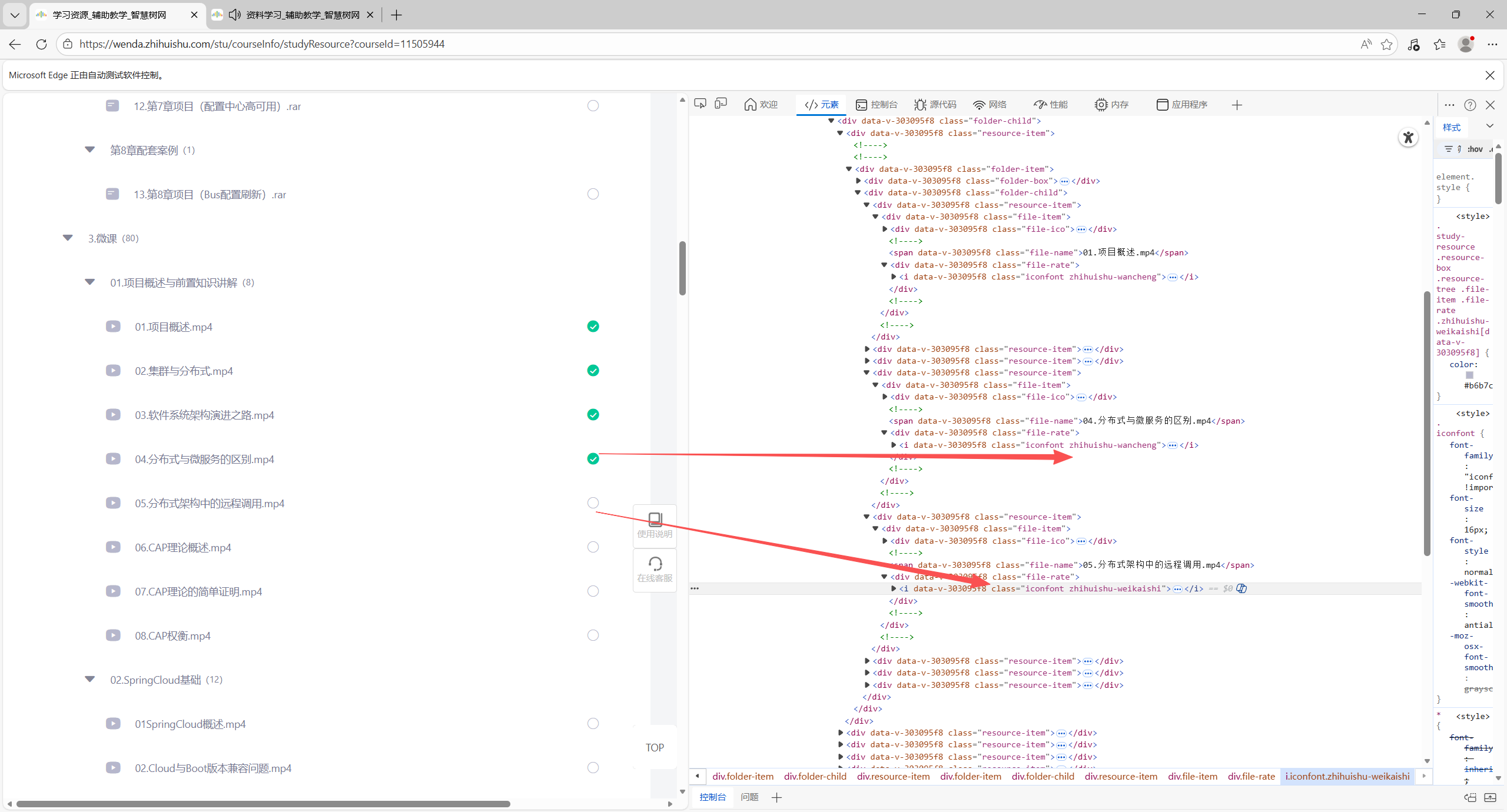
从图中可以看出,只有“已完成的课程”有”.iconfont.zhihuishu-wancheng”,则在轮询时排除掉相关视频即可。
1
2
3
4
5
6
7
8
9
10
11
12
| file_elements = driver.find_elements(By.CLASS_NAME,"file-item")
for file_element in file_elements:
file_name_element = file_element.find_element(By.CSS_SELECTOR, "span.file-name")
try:
file_rate = file_element.find_element(By.CLASS_NAME, "file-rate")
icons = file_rate.find_elements(By.CSS_SELECTOR, ".iconfont.zhihuishu-wancheng")
except Exception:
icons = []
if "mp4" in file_name_element.text and not icons:
print(f"队列中视频:{file_name_element.text}")
|
While True循环播放所有视频
此处的original_window为跳转前的页面,即课程页面而非视频页面,因为Selenium在页面跳转后需要手动修改操作的对象页面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| original_window = driver.current_window_handle
for file_element in file_elements:
try:
file_name_element = file_element.find_element(By.CSS_SELECTOR,"span.file-name")
file_rate = file_element.find_element(By.CLASS_NAME, "file-rate")
icons = file_rate.find_elements(By.CSS_SELECTOR, ".iconfont.zhihuishu-wancheng")
except Exception:
icons = []
if "mp4" in file_name_element.text and not icons:
file_name_element.click()
for window_handle in driver.window_handles:
if window_handle != original_window:
driver.switch_to.window(window_handle)
break
time.sleep(10)
driver.find_element(By.CLASS_NAME,"videoArea").click()
while True:
cur_time = driver.find_element(By.CLASS_NAME,"currentTime").text
duration = driver.find_element(By.CLASS_NAME,"duration").text
print(f"当前进度:{cur_time}/{duration}")
if cur_time == duration and cur_time!="" and duration!="":
break
time.sleep(3)
driver.close()
driver.switch_to.window(original_window)
|
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| import time
from selenium import webdriver
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Edge()
driver.get("https://wenda.zhihuishu.com/stu/courseInfo/studyResource?courseId=11505944")
driver.find_element(By.NAME,"username").send_keys("")
driver.find_element(By.NAME,"password").send_keys("")
driver.find_element(By.CSS_SELECTOR,"span.wall-sub-btn").click()
while True:
if driver.title == "智慧树在线教育_全球大型的学分课程运营服务平台":
time.sleep(1)
print("轮询等待用户登录")
else :
break
courseId= "11505944"
driver.get(f"https://wenda.zhihuishu.com/stu/courseInfo/studyResource?courseId={courseId}")
time.sleep(5)
file_elements = driver.find_elements(By.CLASS_NAME,"file-item")
for file_element in file_elements:
file_name_element = file_element.find_element(By.CSS_SELECTOR, "span.file-name")
try:
icons = file_element.find_elements(By.CSS_SELECTOR, "file-rate.iconfont.zhihuishu-wancheng")
except Exception:
icons = []
if "mp4" in file_name_element.text and not icons:
print(f"队列中视频:{file_name_element.text}")
original_window = driver.current_window_handle
for file_element in file_elements:
try:
file_name_element = file_element.find_element(By.CSS_SELECTOR,"span.file-name")
file_rate = file_element.find_element(By.CLASS_NAME, "file-rate")
icons = file_rate.find_elements(By.CSS_SELECTOR, ".iconfont.zhihuishu-wancheng")
except Exception:
icons = []
if "mp4" in file_name_element.text and not icons:
file_name_element.click()
for window_handle in driver.window_handles:
if window_handle != original_window:
driver.switch_to.window(window_handle)
break
time.sleep(10)
driver.find_element(By.CLASS_NAME,"videoArea").click()
while True:
cur_time = driver.find_element(By.CLASS_NAME,"currentTime").text
duration = driver.find_element(By.CLASS_NAME,"duration").text
print(f"当前进度:{cur_time}/{duration}")
if cur_time == duration and cur_time!="" and duration!="":
break
time.sleep(3)
driver.close()
driver.switch_to.window(original_window)
time.sleep(5)
if __name__ == "__main__":
main()
|