Agent开发——屏幕轮询,在单次屏幕获取的基础上现已支持轮询
前言
本篇是Agent开发——屏幕获取后续。
终于,我的小项目要支持和Neuro-Sama一样的游戏陪玩功能辣!
原理
原理非常简单,如果你使用的LLM支持多模态的图像理解的功能,那么就更加简单了,当然没有上述功能也没关系,同样有解决方案。
LLM支持图像理解
显然,支持图像理解的LLM直接定时获取屏幕截图放入message即可,非常简单的实现。
流程图如下:
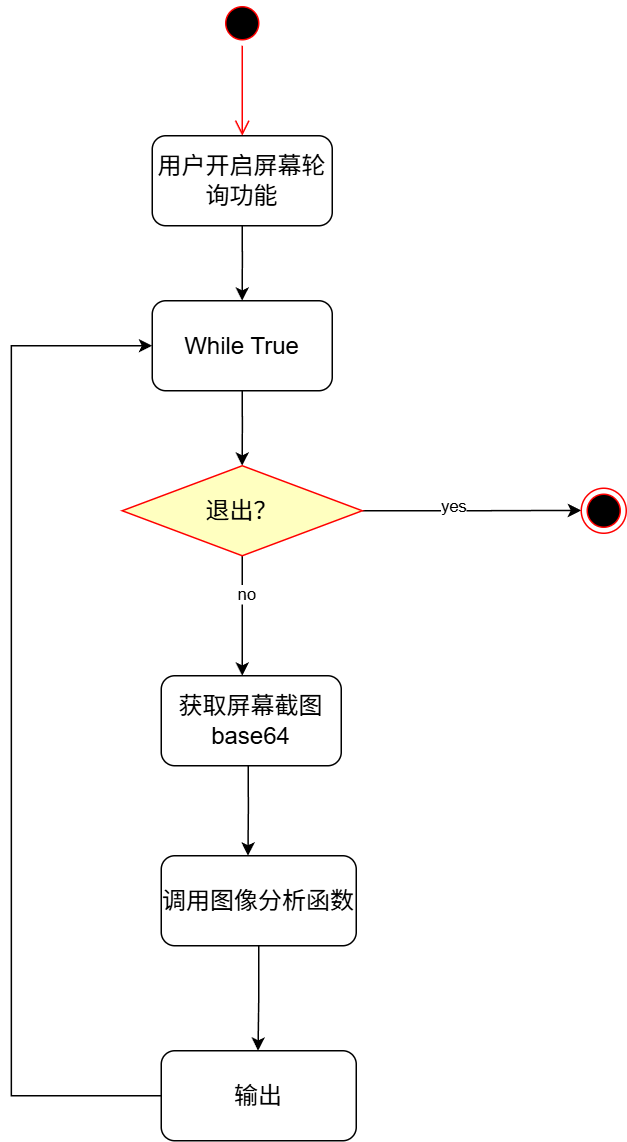
不支持图像理解的LLM
主Agent可以不支持图像理解,但是你不能没有支持图像理解的VLM(视觉语言模型)。
有了VLM,显然要做的就是将图片喂给VLM,然后将VLM输出的图像信息再喂给主Agent
流程图如下:
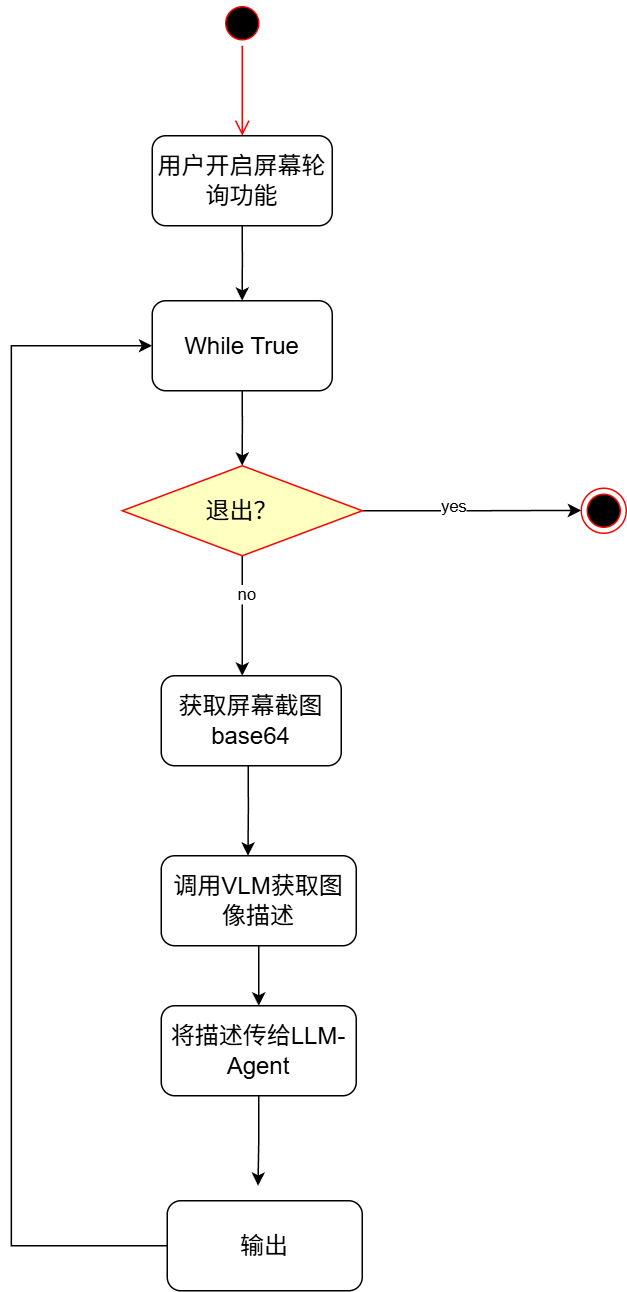
显然,这样做一次中转的弊端是非常明显的,VLM无法把握应该识别的图像关键信息,并且再将信息传递给主Agent的过程也会让信息的损失非常严重,导致最后的效果很差。
而使用多模态的LLM呢,它在识别图像的时候会 根据上下文 来抓住重点,这就很NB了,前面VLM的识别结果可是没有上下文的(也可以有,但它只是个图像识别,并且这样开两个长上下文的LLM效率也十分低下)。
实现
支持图像理解的LLM
和此前的邮件、时间、游戏进程监听一样,本质是while true:
注意设置轮询时间
1
2
3
4
5
6
7
8
9
10
11
| def game_listen_circle_agent():
"""按时间轮询用户屏幕获取信息"""
print("屏幕监听启动")
while True:
time.sleep(10)
if game_listening==0:
print("退出屏幕监听")
break
uri = pic_cap()
llm.picture_analysis(uri,"这是用户的屏幕截图,请你根据截图的内容与Master主动对话,或是吐槽、或是闲谈,尤其是master正在打游戏时,可以主动往游戏话题上靠,注意话不要太多,最好不要超过80字")
time.sleep(50)
|
picture_analysis:
注意此处的入参pic_url,传入的是图片的url(地址)则转为base64,若不是,则按原样传递(即原本是base64那就不用转),因为这个函数我还在普通的图像问答中复用了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| def picture_analysis(pic_url: str, input: str):
"""对图片进行分析并返回模型的文本回答。"""
prompt = input
global messages
if os.path.exists(pic_url):
mime = mimetypes.guess_type(pic_url)[0] or "image/png"
with open(pic_url, "rb") as f:
b64 = base64.b64encode(f.read()).decode()
image_repr = f"data:{mime};base64,{b64}"
else:
image_repr = pic_url
msg = {"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image_repr}},
]}
messages.append(msg)
res = get_agent_nopic().invoke({
"messages":messages
})
latest_message = res["messages"][-1]
if latest_message.content:
res=latest_message.content.strip()
return res
|
在main.py中绑定”屏幕监听”按键的轮询开关:
1
2
3
4
5
6
7
8
9
10
11
| def game_mode(self):
"""启动屏幕监听线程"""
if game_mode.game_mode.game_listening == 0:
game_mode.game_mode.game_listening=1
self.ui.gameButton.setText("停止监听")
listener_thread = threading.Thread(target=game_mode.game_mode.game_listen_circle_agent, daemon=True)
listener_thread.start()
print('[INFO] 启动屏幕监听线程')
elif game_mode.game_mode.game_listening==1:
game_mode.game_mode.game_listening=0
self.ui.gameButton.setText("屏幕监听")
|
主Agent+VLM
直接从头写了一个很长的函数,本质就是先VLM获取中段识别结果,再用主Agent获取对话内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| def game_listen_circle_depart():
"""按时间轮询用户屏幕获取信息"""
print("屏幕监听启动")
while True:
time.sleep(10)
if game_listening==0:
print("退出屏幕监听")
break
uri = pic_cap()
response = llm.pic_agent.chat.completions.create(
model="glm-4.6v-flash",
messages=[
{
"content": [
{
"type": "image_url",
"image_url": {
"url": uri
}
},
{
"type": "text",
"text": "这是用户屏幕的截图,详细描述图片上的内容,尤其是与游戏相关的画面要详细描述,仅仅是描述即可,不要有其他任何多余的输出,仅输出'这张图片描述了xxxxxx'即可"
}
],
"role": "user"
}
],
thinking={
"type": "disabled"
}
)
res = response.choices[0].message.content or ""
if not isinstance(res, str):
res = str(res)
print(f"中段vlm识别结果:{res}")
global game_msgs
safe_messages = []
for msg in game_msgs:
role = msg.get("role", "user")
content = msg.get("content", "")
if not isinstance(content, str):
content = "" if content is None else str(content)
safe_messages.append({"role": role, "content": content})
game_msgs = safe_messages
master_input = f"[game_screen]{res}"
game_msgs.append({
"role": "user",
"content": f"你已进入游戏监听模式,在此模式下你将不时收到master的屏幕内容描述,请你根据master屏幕的内容做出合适的对话,或是吐槽、或是闲谈,内容如下{res}"
})
agent_result = llm.get_agent().invoke({
"messages":game_msgs
})
print(agent_result)
latest_message = agent_result["messages"][-1]
content = latest_message.content
if isinstance(content, str):
result = content.strip()
elif content is None:
result = ""
else:
result = str(content).strip()
game_msgs.append({
"role": "assistant",
"content": result
})
print(result)
time.sleep(50)
|
效果
仅展示第一种支持多模态LLM方法的效果,第二种的效果就算了吧。。。
杀戮尖塔2陪玩
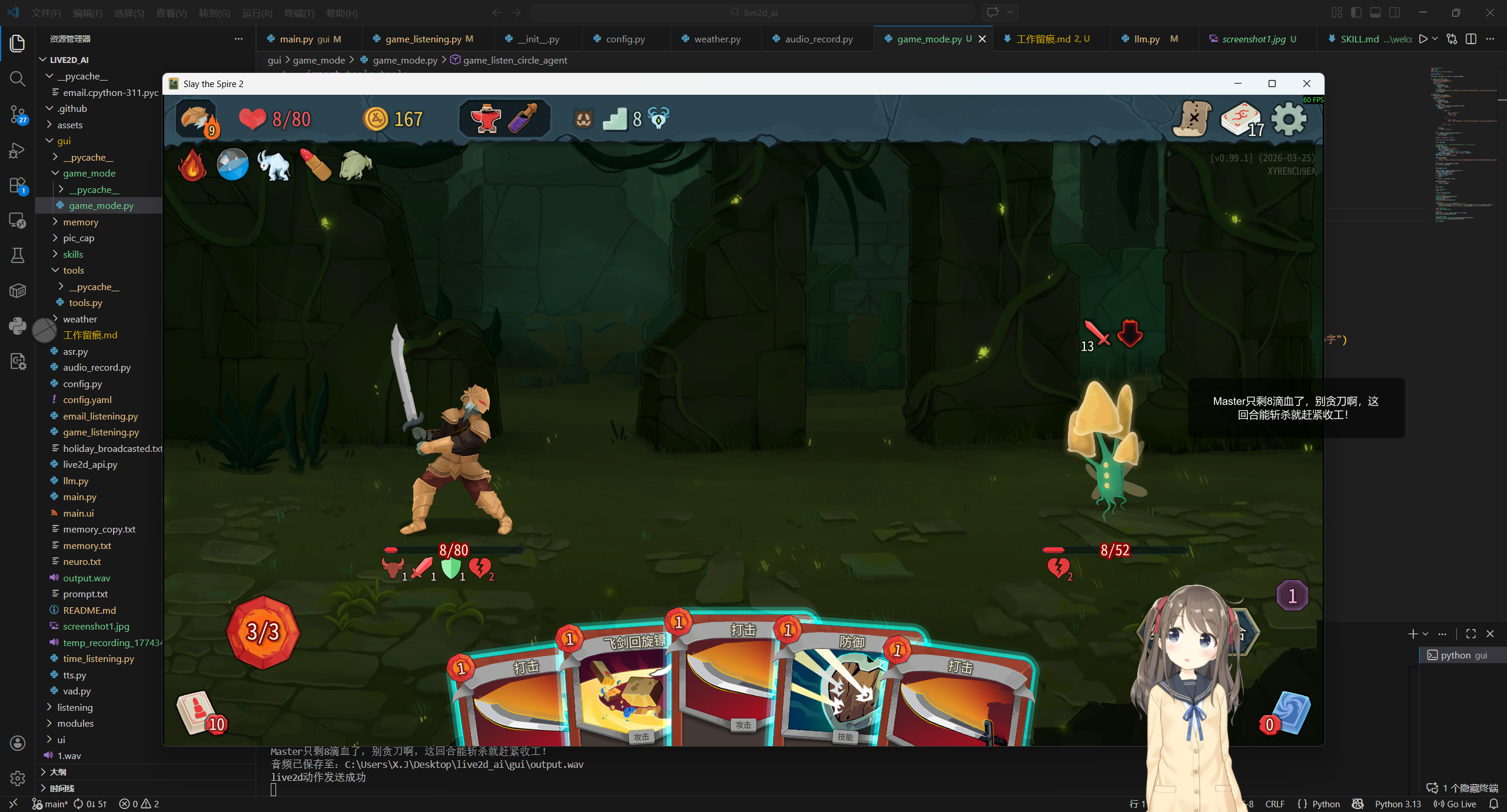
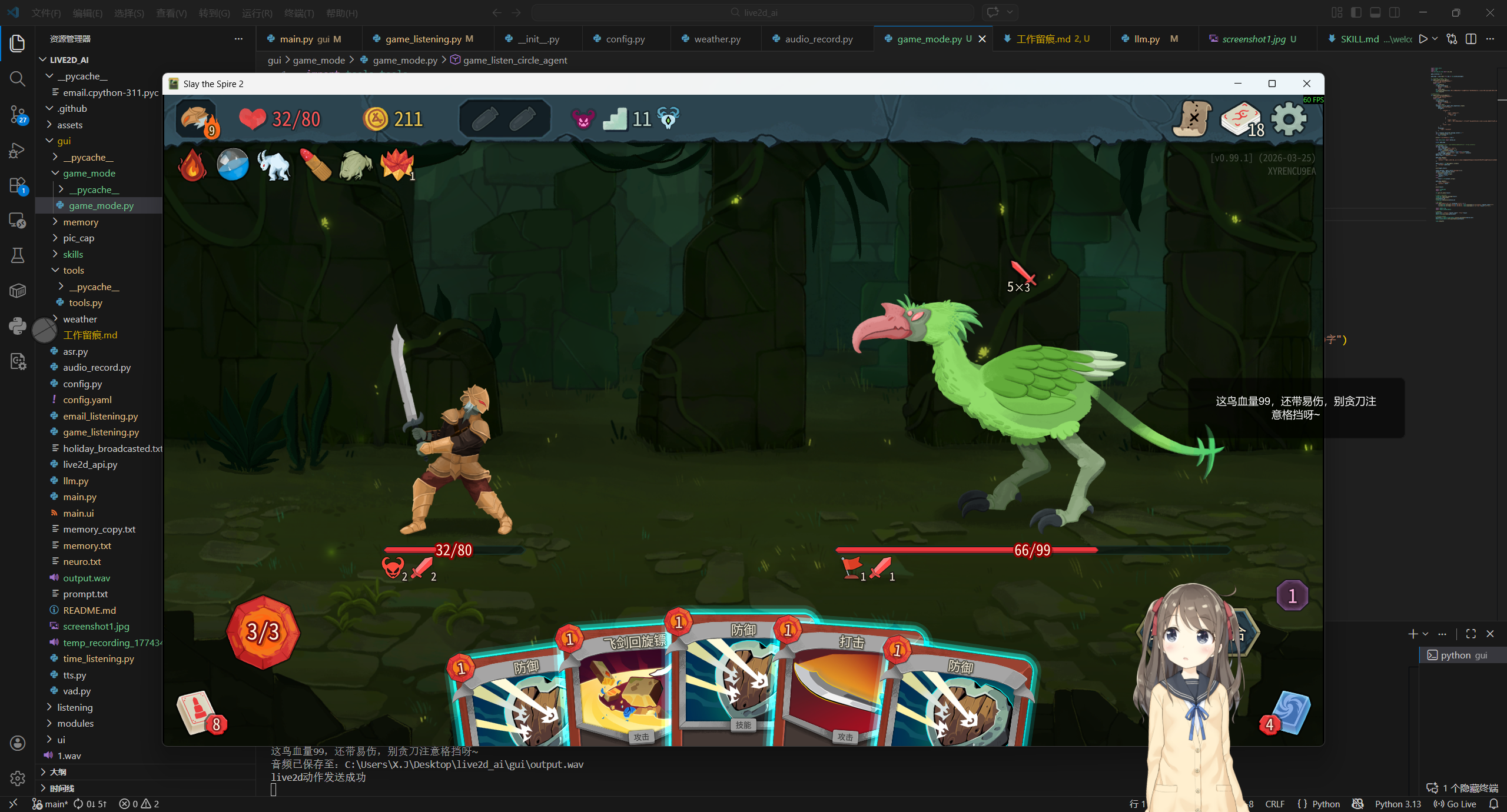
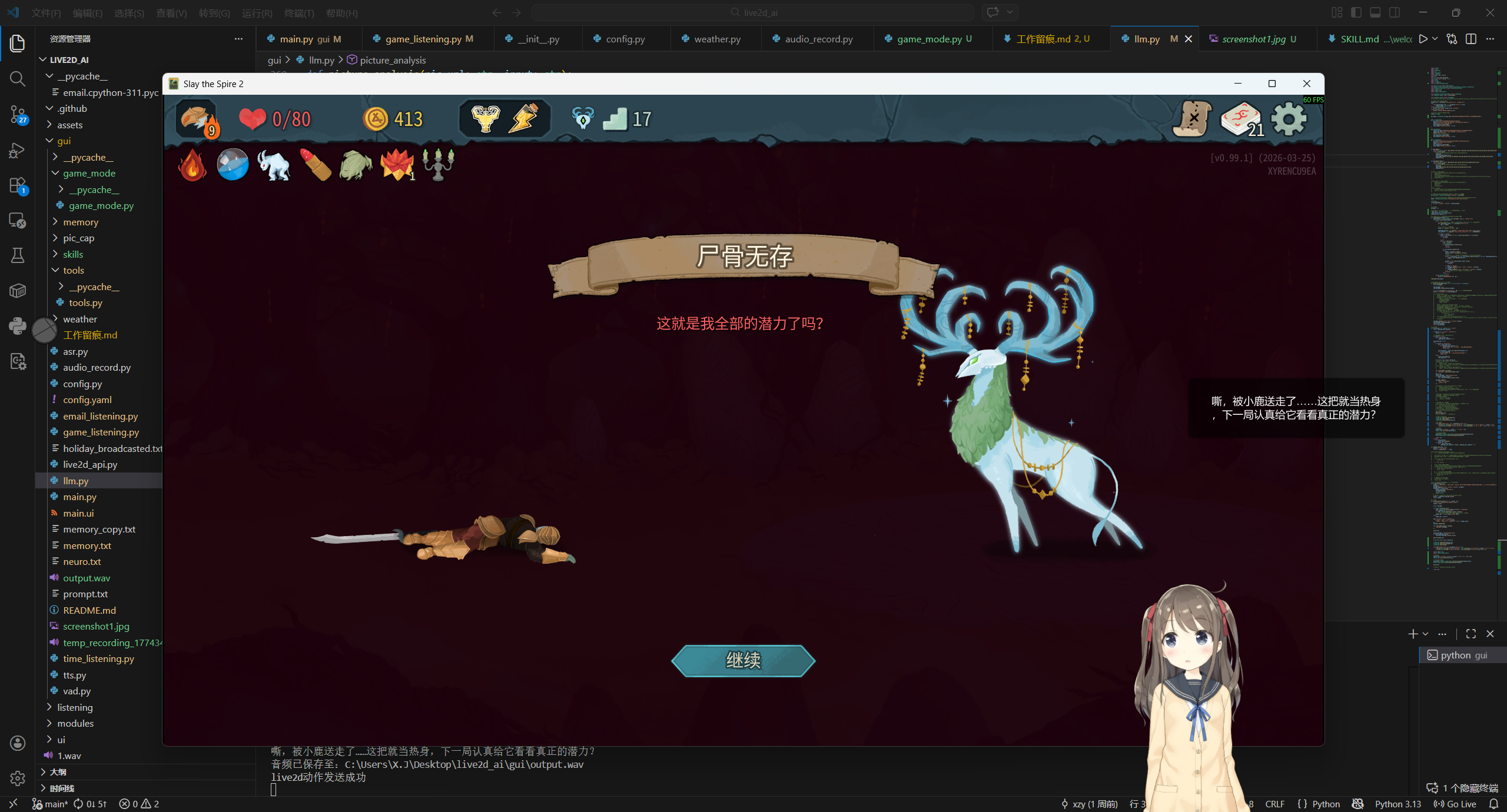
当然这是在没有知识库的情况下,如果能有个游戏对应的知识库的话,针对游戏画面的内容的理解会更加深刻,对话效果还会更好。
工作陪伴
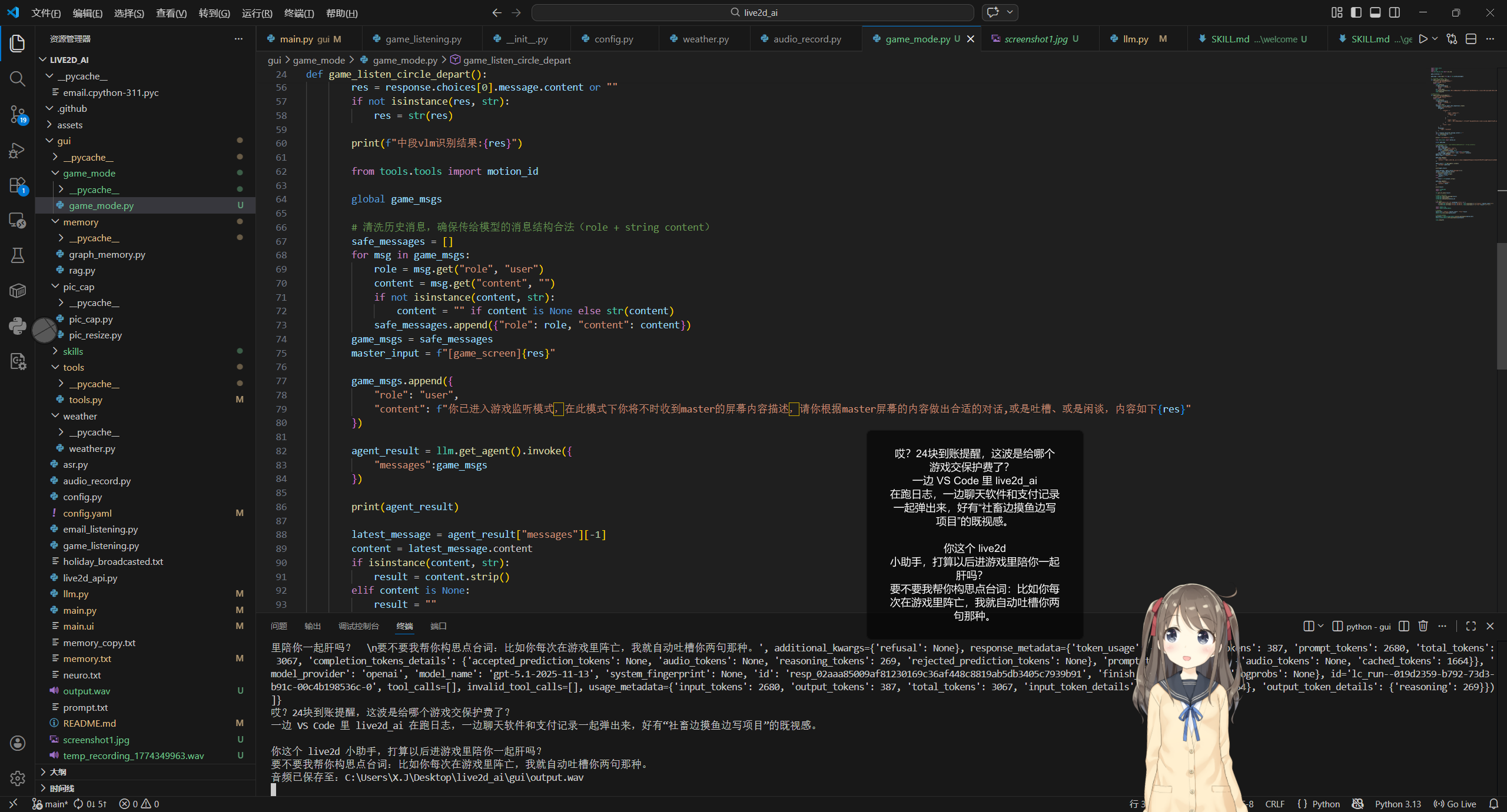
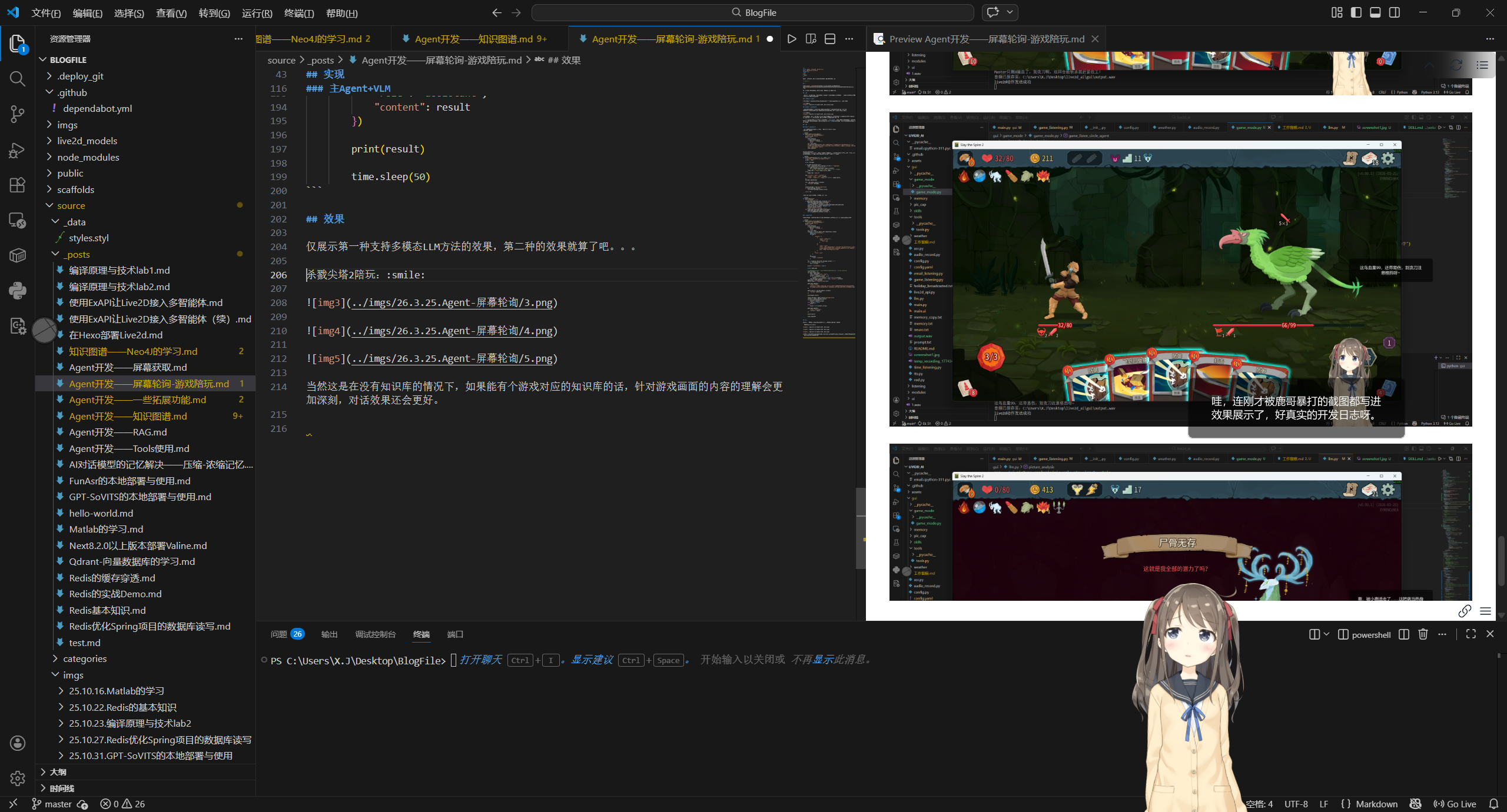
总结
总的来说效果还是很惊艳的,至少我自己之后会开着这个屏幕轮询去工作/玩游戏了。
未来可能会接入一些特定游戏的知识库来提供更加完善的陪玩体验,甚至在有了知识库之后能否通过高频次的屏幕轮询去亲自玩一些交互性较为简单的游戏(Galagme,卡牌游戏等)呢?
待解决的问题
屏幕轮询模式下用户主动发起对话,二者之间的冲突如何解决。