# 创建唯一性约束确保数据一致性 constraints = [ "CREATE CONSTRAINT Person IF NOT EXISTS FOR (p:Person) REQUIRE p.name IS UNIQUE", "CREATE CONSTRAINT Position IF NOT EXISTS FOR (po:Position) REQUIRE po.name IS UNIQUE", "CREATE CONSTRAINT Organization IF NOT EXISTS FOR (o:Organization) REQUIRE o.name IS UNIQUE", "CREATE CONSTRAINT Item IF NOT EXISTS FOR (i:Item) REQUIRE i.name IS UNIQUE", "CREATE CONSTRAINT Concept IF NOT EXISTS FOR (c:Concept) REQUIRE c.name IS UNIQUE", "CREATE CONSTRAINT Time IF NOT EXISTS FOR (t:Time) REQUIRE t.name IS UNIQUE", "CREATE CONSTRAINT Event IF NOT EXISTS FOR (e:Event) REQUIRE e.name IS UNIQUE", "CREATE CONSTRAINT Activity IF NOT EXISTS FOR (a:Activity) REQUIRE a.name IS UNIQUE" ]
for constraint in constraints: get_graph().run(constraint)
res = get_agent_nopic().invoke({ "messages":msgs })
latest_message = res["messages"][-1] if latest_message.content: res=latest_message.content.strip() quintuples = json.loads(res) print(f"提取到 {len(quintuples)} 个五元组") print([tuple(t) for t in quintuples iflen(t) == 5]) return [tuple(t) for t in quintuples iflen(t) == 5]
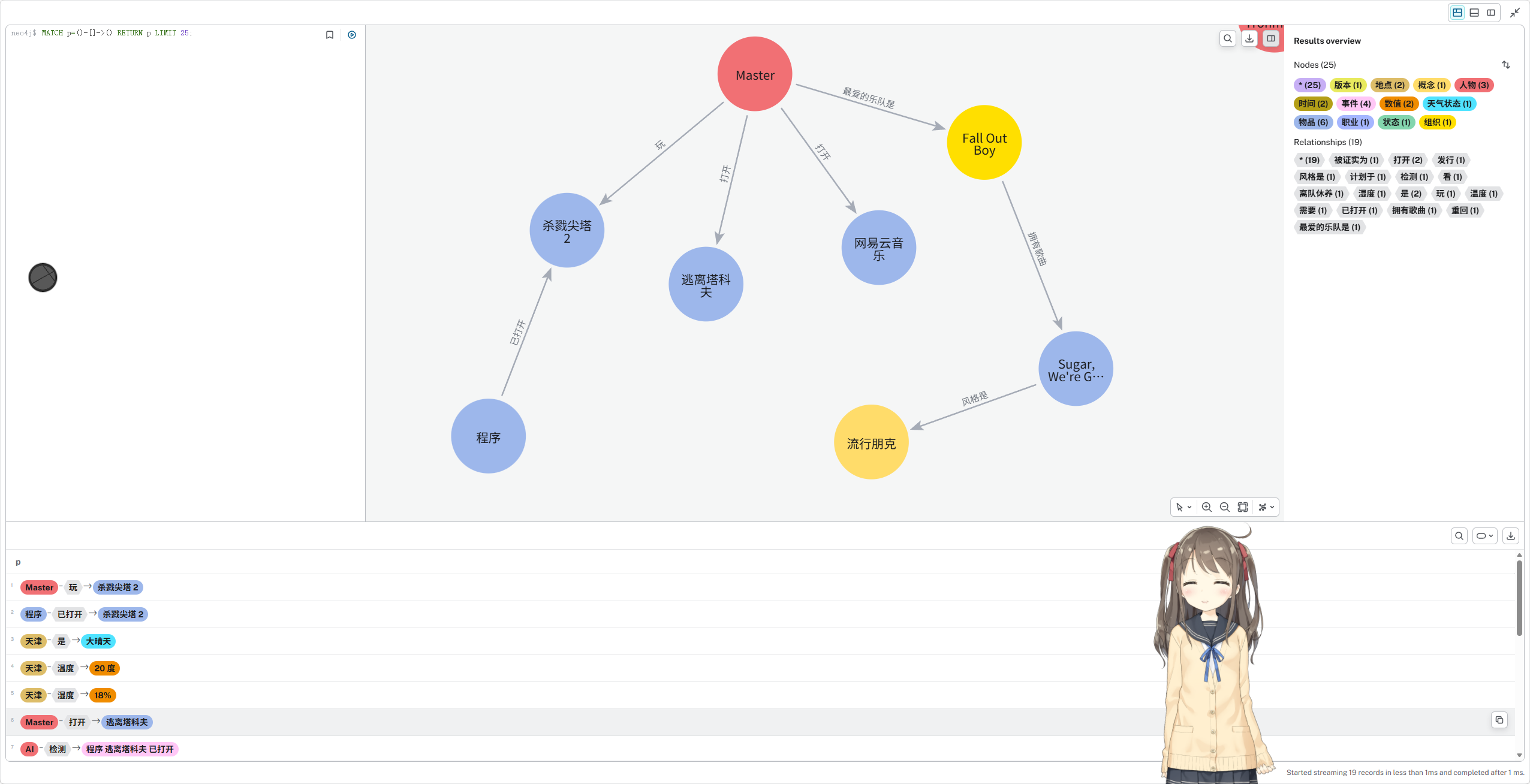
用户输入:我最爱的乐队是Fall Out Boy AIMessage(content="Fall Out Boy啊!那首《Sugar, We're Goin Down》可是超级经典呢。 看来Master喜欢这种充满活力的流行朋克风格?下次要不要一起听听他们的新专辑,或者聊聊你最 喜欢他们的哪首歌?" ........)
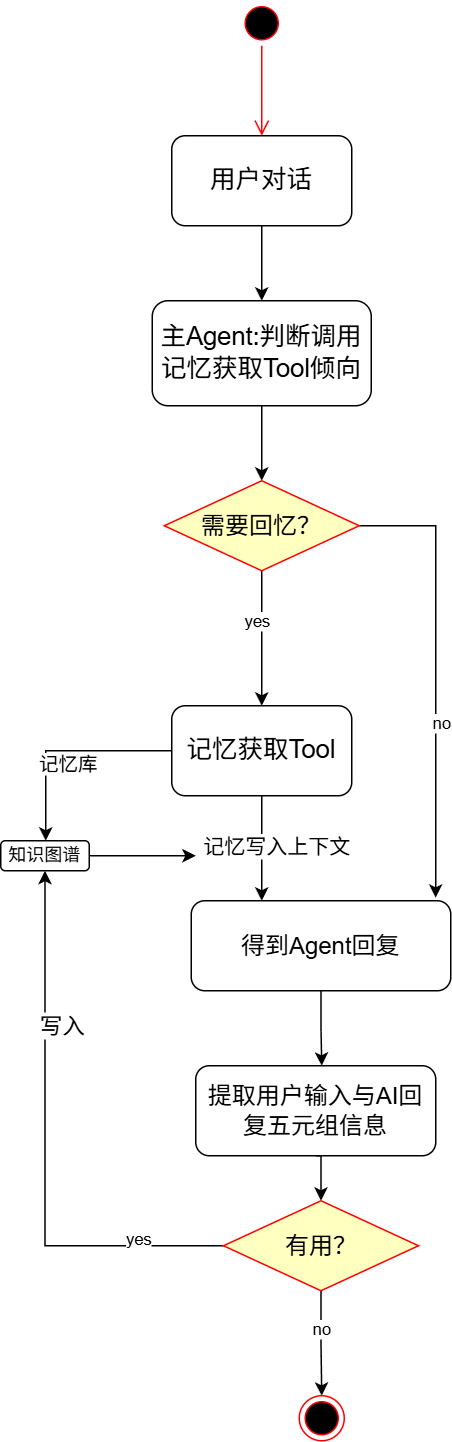
对话结束后启动五元组分割
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
提取到 3 个五元组 [('Master', '人物', '最爱的乐队是', 'Fall Out Boy', '组织'), ('Fall Out Boy', '组织', '拥有歌曲', "Sugar, We're Goin Down", '物品'), ("Sugar, We're Goin Down", '物品', '风格是', '流行朋克', '概念')] 存储开始: 主语: Master (类型: 人物) 谓语: 最爱的乐队是 宾语: Fall Out Boy (类型: 组织) --- 主语: Fall Out Boy (类型: 组织) 谓语: 拥有歌曲 宾语: Sugar, We're Goin Down (类型: 物品) --- 主语: Sugar, We're Goin Down (类型: 物品) 谓语: 风格是 宾语: 流行朋克 (类型: 概念) ---