Agent开发——屏幕获取,让AI识别你屏幕的信息
前言
动机来源:首先,毫无疑问的是Neuro-Sama,在Vedel打游戏的时候能够识别屏幕信息并做出吐槽,其实Neuro早在两年前就已经能打游戏了,不清楚使用的是视觉识别还是直接读游戏内存【Neuro】AI对杀戮尖塔的顶级理解.
此外,也来源于–ai妹妹无信息知晓敌人数量与位置,一个叫 妹居物语 的AI陪伴应用的桌宠模式,也能够做到上述Neuro-sama的功能.
本质上来说这实现起来并不复杂
原理
目前市面上的很多AI都已经有了多模态的功能,他们不单单是LLM,同时集成了图像识别的功能,现在实现起来就简单多了.
实现上述功能的流程图如下:
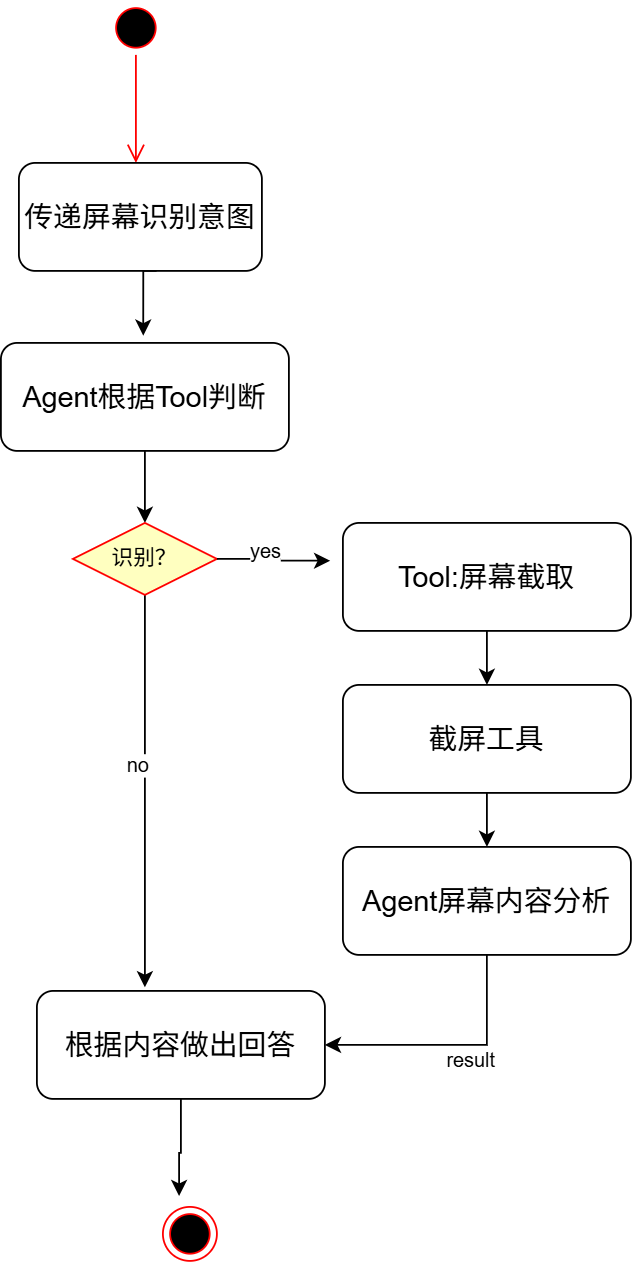
即正常的Tool调用流程,重点在于Tool的实现.
实现
屏幕截取
调用个库截取一下即可,真正的问题在于你截取了屏幕之后如何传递给Agent
参见阿里云 千问模型的文档 图像与视频理解
其中说到,有两种方法,一种是传base64,一种是本地传路径,但是本地传路径的方法不适用于OpenAI方式,所以我们只能采用base64传图.
下面代码也在图片截取之后做了转base64的操作,函数返回值也是对应的base64
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import base64
import mimetypes
import os
import numpy as np
from PIL import ImageGrab, Image
import cv2
from . import pic_resize
import tkinter as tk
def pic_cap():
root = tk.Tk()
screen_width = root.winfo_screenwidth()
screen_height = root.winfo_screenheight()
img = ImageGrab.grab(bbox=(0, 0,screen_width, screen_height))
print(img.size[1], img.size[0])
img = np.array(img.getdata(), np.uint8).reshape(img.size[1], img.size[0], 3)
print("屏幕获取成功!")
img=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
cv2.imwrite('screenshot1.jpg', img)
pic_size = pic_resize.pic_compress('screenshot1.jpg', 'screenshot1.jpg', target_size=200)
print("图片压缩后的大小为(KB):", pic_size)
if os.path.exists("screenshot1.jpg"):
mime = mimetypes.guess_type("screenshot1.jpg")[0] or "image/png"
with open("screenshot1.jpg", "rb") as f:
b64 = base64.b64encode(f.read()).decode()
image_repr = f"data:{mime};base64,{b64}"
else:
image_repr = "screenshot1.jpg"
return image_repr
|
图片压缩部分代码,节省些token吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| from io import BytesIO
import cv2
import numpy as np
def pic_compress(pic_path, out_path, target_size=199, quality=90, step=5, pic_type='.jpg'):
with open(pic_path, 'rb') as f:
pic_byte = f.read()
img_np = np.frombuffer(pic_byte, np.uint8)
img_cv = cv2.imdecode(img_np, cv2.IMREAD_ANYCOLOR)
current_size = len(pic_byte) / 1024
print("图片压缩前的大小为(KB):", current_size)
while current_size > target_size:
pic_byte = cv2.imencode(pic_type, img_cv, [int(cv2.IMWRITE_JPEG_QUALITY), quality])[1]
if quality - step < 0:
break
quality -= step
current_size = len(pic_byte) / 1024
with open(out_path, 'wb') as f:
f.write(BytesIO(pic_byte).getvalue())
return len(pic_byte) / 1024
|
首先,何时调用此Tool.
因为我们是小项目并且是用的外部API,所以我们在此将屏幕识别的触发设定为:用户在对话框输入”看看我在做什么”这类的被动方式.
想要做到我们在前言提到的效果,可以使用轮询的方式主动不间断获取屏幕画面,当然这样的Token开支是巨大的.
具体的实现思路为:
Agent检测到用户批准”屏幕识别”的意图 -> 触发Tool -> 截图并返回Base64图像信息 -> 调用第三方Agent(这里为我们创建的Agent二号机)获取图像分析结果 -> 带着结果返回给Agent
调用第三方Agent(这里为我们创建的Agent二号机)获取图像分析结果:
这样做而不直接把Base64喂给原Agent的原因是,直接将Base64作为Tool的结果返回,会被识别为str而不是图像( 千万不要这样做 会直接把token用光)
目前只想到这样用另一个Agent去做一个识别文本的中转,不清楚是否有更好的实现方法
Prompt
1
2
3
4
5
| get_screenshot_tool
- 核心能力:无入参,截取用户屏幕并根据屏幕图片内容和用户输入以及上下文进行对话;
- 出参:图片的详细描述
- 使用场景:当用户谈到涉及“看看我的屏幕”,“结合我的屏幕”,“看我玩的这个游戏”,“你看看这个网页”等涉及要求你获取屏幕信息的场景;
- 示例:user:“猜猜我在电脑上干什么”,调用工具识别用户桌面,并结合出参结合上下文与人设与用户对话;
|
这里的agent_nopic为Agent二号机,专门用于做图像识别结果中转
为什么不直接用原有的Agent做这次图像识别?
因为原有的Agent带着get_screenshot_tool方法,而在输入涉及”用户屏幕”等词的时候,有有可能会调用该Tool导致循环嵌套,所以做中段识别应该交给一个什么Tool也没有的Agent来做.
agent_nopic就是我新创建的不含任何Tool的Agent
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @tool(description="捕获用户桌面并响应")
def get_screenshot_tool():
img_data_uri = pic_cap()
msg = {"role": "user", "content": [
{"type": "text", "text": "这是用户屏幕的截图,详细描述图片上的内容,仅仅是描述即可,不要有其他任何多余的输出,仅输出'这张图片描述了xxxxxx'即可"},
{"type": "image_url", "image_url": {"url": img_data_uri}},
]}
llm.messages.append(msg)
res = llm.agent_nopic.invoke({
"messages":llm.messages
})
latest_message = res["messages"][-1]
if latest_message.content:
res=latest_message.content.strip()
print("图像识别Tool中段输出:"+res)
return res
|
使用效果
这是我触发屏幕识别时的截图
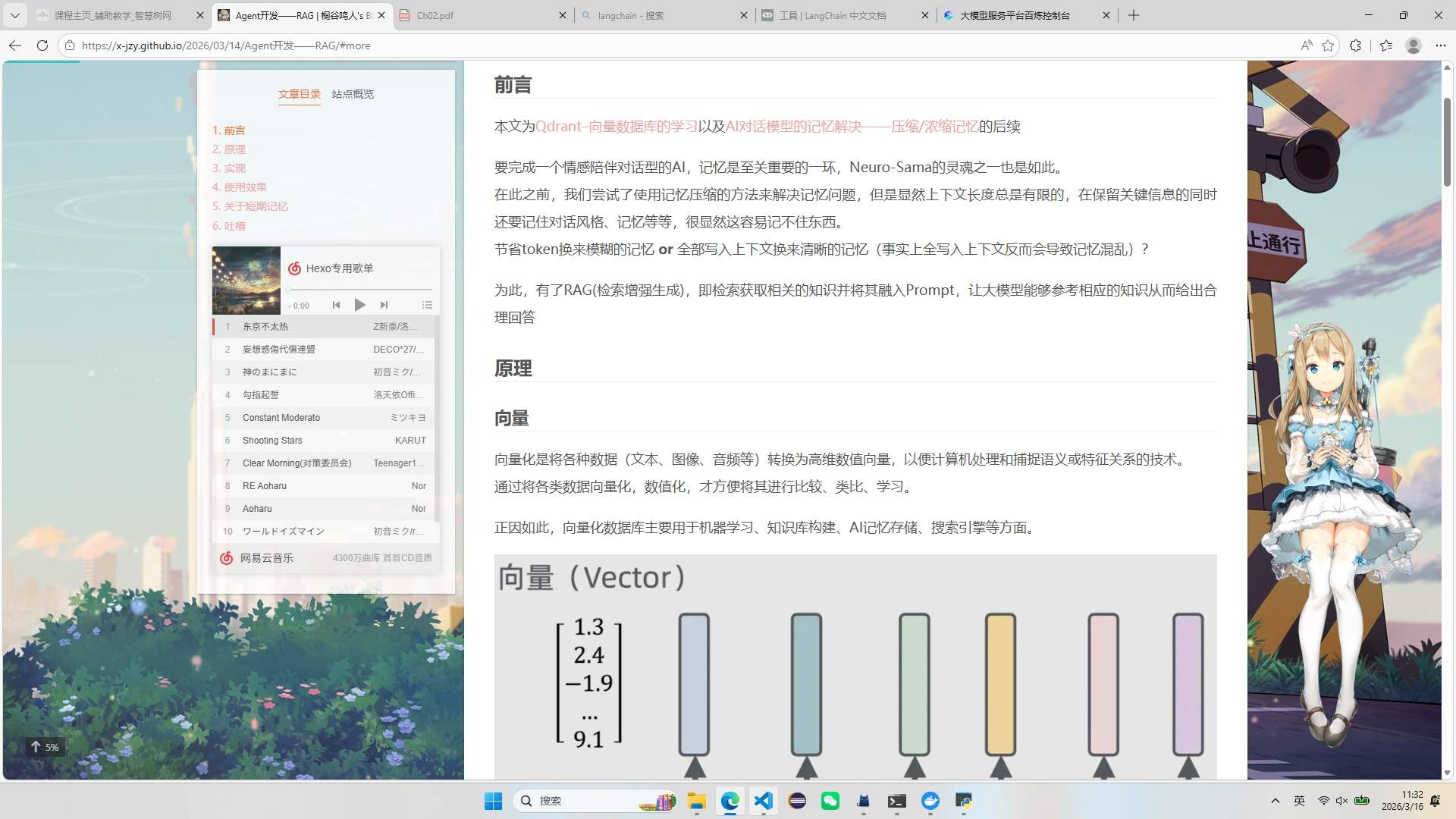
tool调用:
1
2
3
4
5
6
7
8
| tool_calls=[
{
'name': 'get_screenshot_tool',
'args': {'input': '看看我的屏幕'},
'id': '17b3c2b3-e250-4a2e-932a-ff4635ac70f1',
'type': 'tool_call'
}
]
|
中段图像识别输出:
1
2
3
4
5
6
7
8
9
10
| ToolMessage(
content='这张图片 展示了用户浏览一个技术主题的网页,
左侧是“文章目录”和音乐播放器界面(显示歌单),
右侧是正文内容关于神经科学主题——主要讲述 RAG 技术和向量
数据库在学习及 AI 记忆处理中的应用。屏幕底部任务栏显示时间为 11:32,
日期为 2026 年 3 月 16 日。',
name='get_screenshot_tool',
id='ee93efb4-d8f3-4d38-b5b1-1c632ebe2369',
tool_call_id='17b3c2b3-e250-4a2e-932a-ff4635ac70f1'
)
|
最终输出
1
2
3
| 好呀!Master 刚才是在看关于神经科学和 RAG 技术的网页哦。
页面里提到了向量数据库怎么帮 AI 记得住记忆呢,好像还讲了怎么用 LLM 来生成知识库,
感觉挺有意思的~ Master 对这方面感兴趣吗?
|