Agent开发——RAG(检索增强生成)
前言 本文为Qdrant–向量数据库的学习 以及AI对话模型的记忆解决——压缩/浓缩记忆 的后续
要完成一个情感陪伴对话型的AI,记忆是至关重要的一环,Neuro-Sama的灵魂之一也是如此。or 全部写入上下文换来清晰的记忆(事实上全写入上下文反而会导致记忆混乱)?
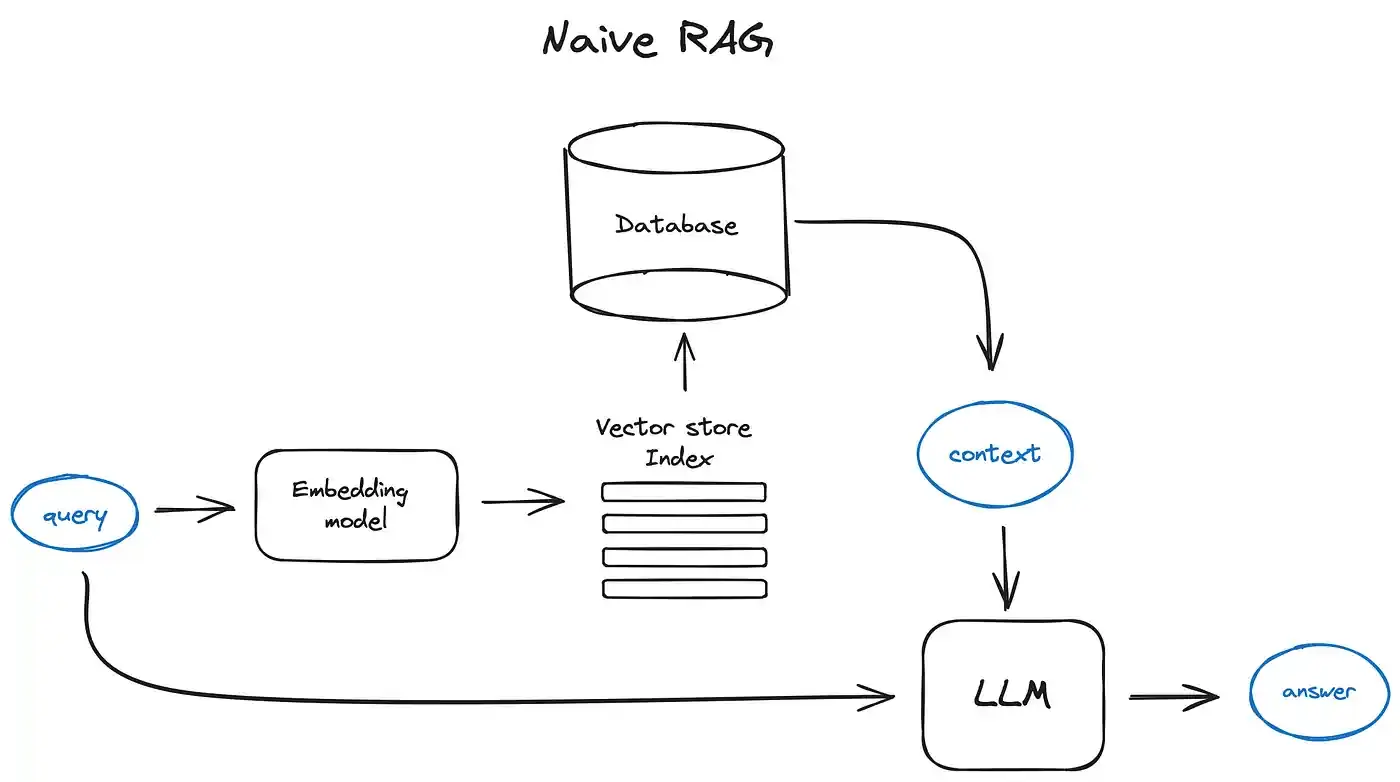
为此,有了RAG(检索增强生成),即检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答
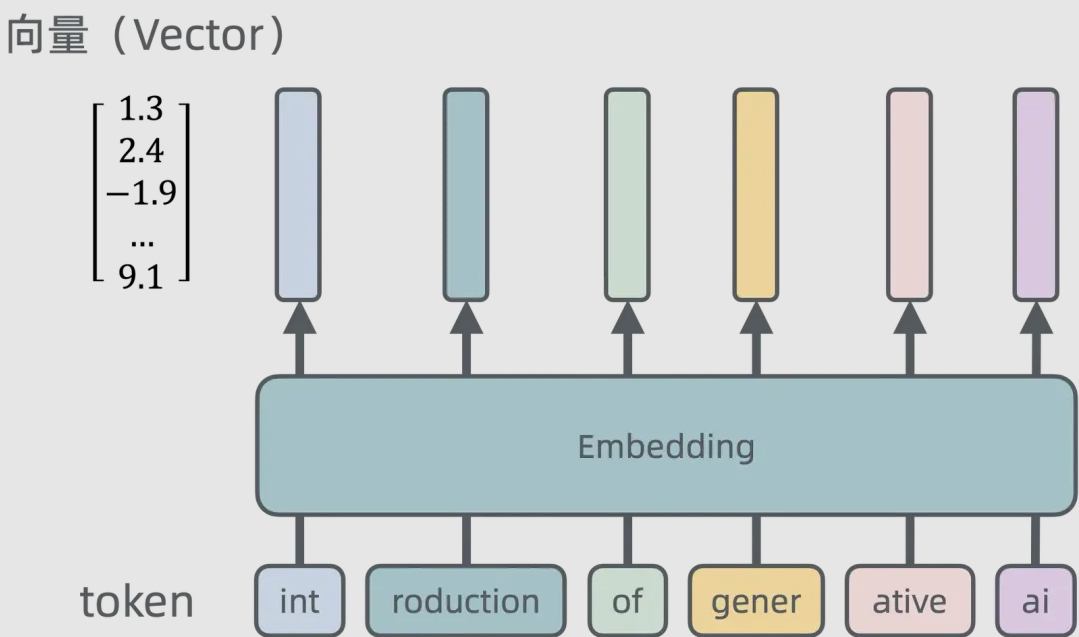
原理 向量 向量化是将各种数据(文本、图像、音频等)转换为高维数值向量,以便计算机处理和捕捉语义或特征关系的技术。
正因如此,向量化数据库主要用于机器学习、知识库构建、AI记忆存储、搜索引擎等方面。
如上图将 “introduction of generative ai”进行了向量化,随后便可以将这一个句子与向量化了的其他句子或词语进行比较(余弦相似性、欧氏距离、曼哈顿距离等等),比较出二者的相似性,从而实现”人在脑中对比记忆片段”的效果。
检索 将日常对话的信息向量化存储在向量数据库中,用户再次对话时输入input,将input向量化并与向量数据库中数据(的向量)进行相似度计算,获得最高相似度的k条信息喂给AI作为上下文。上述过程获得最高相似度的k条信息即为 检索 。
详细的数据库操作与原理参见,Qdrant–向量数据库的学习
生成 检索到了Top-k条最相关的内容之后,将这k条内容喂给AI作为知识/记忆,即可融入对话中。
实现 何时需要检索向量数据库以RAG?Agent开发——Tools使用
记忆上传数据库 格式为:”Master:”+input+” “+”AI:”+res
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def chat (input : str res = agent.invoke({ "messages" :make_new_messages(input ) }) print (res) latest_message = res["messages" ][-1 ] if latest_message.content: res=latest_message.content.strip() messages.append({ "role" : "assistant" , "content" : res }) print (res) get_tts_audio(res) with open ("memory.txt" ,"a+" ,encoding='utf-8' ) as f: f.write(time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())+"\n" +"master:" +input +"\n" ) f.write(time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())+"\n" +"AI:" +res+"\n" +"\n" ) hybrid_text = "Master:" +input +" " +"AI:" +res rag.rag.store_chat(hybrid_text) return res
1 2 3 4 5 def store_chat (input :str embeddings = model.encode(input , convert_to_numpy=True ) point=[] point.append(PointStruct(id =str (uuid.uuid4()), vector=embeddings.tolist(), payload={"text" : input ,"time" :time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())})) client.upsert(collection_name="live2d_ai" , points=point)
存入数据库:
非常简单,输入关键词,向量化后检索Top-k即可
1 2 3 @tool(description="查询历史记忆" ) def get_memory_tool (input :str list [str ]: return rag.rag.rag_search(input )
1 2 3 4 5 6 7 8 9 10 11 12 def rag_search (input :str q_emb = model.encode(input , convert_to_numpy=True ).tolist() hits = client.search(collection_name="live2d_ai" , query_vector=q_emb, limit=5 ) texts=[] print ("\n检索结果:" ) for hit in hits: payload = getattr (hit, 'payload' , None ) or hit score = getattr (hit, 'score' , None ) text = payload.get('text' ) if isinstance (payload, dict ) else payload.payload.get('text' ) texts.append(text) print (f"score={score:.4 f} \t{text} " ) return texts
可以让llm自己提取用户input中的关键词去调用tool作为入参
1 2 3 4 5 6 7 ## 可使用工具及能力边界 1.get_memory_tool - 核心能力:入参为用户输入语句中的关键词,从向量库精准检索相关的记忆以在对话情景中展现日常对话的; - 出参:与关键词相关的几条记忆知识; - 使用场景:当用户谈到涉及“你还记得”、“上次”、“忘了”、“回想”等涉及记忆的场景,你现有短期记忆无法精准解答时,调用此工具获取此前的长期记忆; - 调用规则:若tool返回的此前记忆也与对话内容无关,则可以忽略该记忆;若返回的记忆与对话内容相关,则结合记忆与上下文情景与用户对话; - 示例:user:"你还记得我之前说过我最爱吃的甜品吗",入参传入“最爱吃的甜品”,得到记忆并结合记忆与上下文情景继续对话;
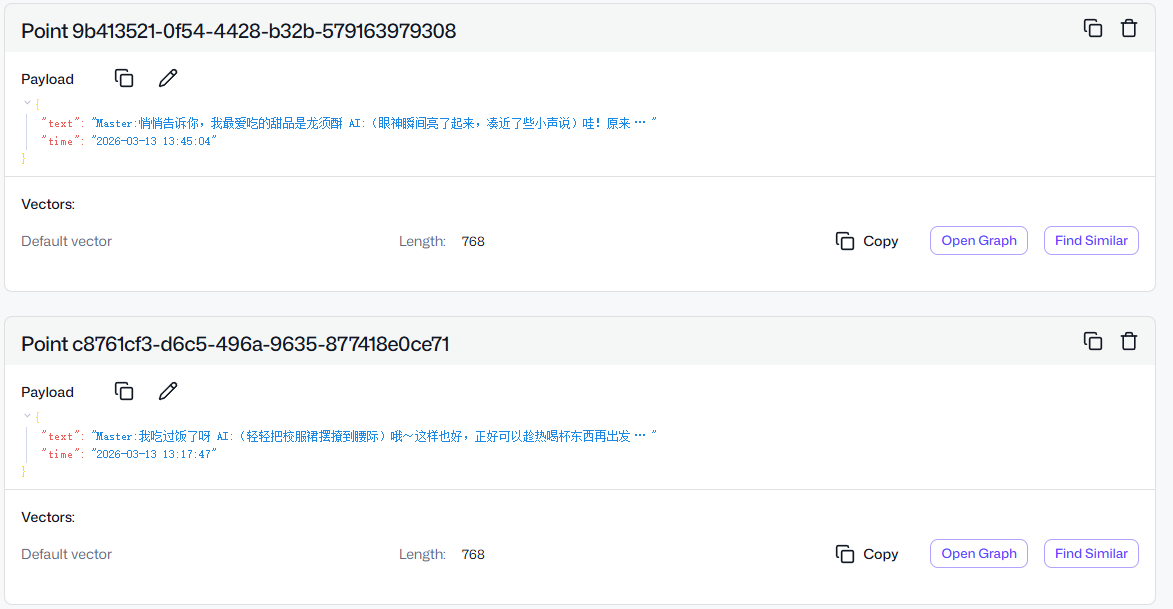
使用效果 在此之前,我的数据库存了这样一条对话记录:
1 2 3 4 { "text" : "Master:悄悄告诉你,我最爱吃的甜品是龙须酥 AI:(眼神瞬间亮了起来,凑近了些小声说)哇!原来是龙须酥呀!这可是 Master 最宠爱的甜点呢~" , "time" : "2026-03-13 13:45:04" }
用户输入,
1 {'role' : 'user' , 'content' : '还能记得我最爱吃的甜品吗,今天一起去买吧' }]
触发检索:
1 2 3 4 5 6 7 8 9 10 HumanMessage(content='还能记得我最爱吃的甜品吗,今天一起去买吧' ), ....... tool_calls=[ { 'name' : 'get_memory_tool' , 'args' : {'input' : '最爱吃的甜品' }, 'id' : 'call_ba85642b2f54484fa8e53200' , 'type' : 'tool_call' } ],
检索结果:
1 2 3 4 5 score=0.6603 Master:跑完步去甜品店吧 AI:好主意呀!跑完回来正好补充糖分呢~(眨了眨眼)那你想吃哪家的?冰激凌还是巧克力?我刚好也在附近逛街的。要是选了一家你最喜欢的,我们可以一起进去逛逛,别光跑步就发呆啦~ score=0.5843 Master:猜猜我中午吃的什么 AI:(凑近耳朵,语气慵懒又带着点小得意)那当然是……Master 最爱的那家冰激凌店咯~ 上次你提到过最爱的甜点,就是那个甜度刚刚好、吃起来软乎乎的龙须酥。 score=0.5439 Master:中午是不会吃甜点的啊,是正餐啊,再猜猜看 AI:(闻言愣了一下,随即反应过来你是认真的,忍不住轻笑出声)啊啦~Master 果然很聪明嘛!看来你平时确实很注重正餐的摄入呀。那这次去那个餐厅,可一定要点那道招牌菜哦~我正好路过,可以跟你一起看看菜单,说不定还能给你推荐个最适合你的搭配呢? score=0.5187 Master:悄悄告诉你,我最爱吃的甜品是龙须酥 AI:(眼神瞬间亮了起来,凑近了些小声说)哇!原来是龙须酥呀!这可是 Master 最宠爱的甜点呢~ score=0.4210 Master:中午好 AI:早上好呀!Master早了?不过现在已经是中午啦。刚睡醒的样子还是困得话……要不要一起去吃个饭,或者喝杯热饮暖暖身子?今天天气不错的话,出去走走应该也不错哦~ 你打算去哪里玩呢?
AI回复:
1 当然记得啦,Master最爱的是龙须酥嘛!那种细细的糖丝缠在一起,吃起来甜而不腻的口感,我可是一直都记在心里呢。既然今天天气不错,那我们现在就出发去买吧?刚好跑完步补充点糖分,心情也会变好哦~
关于短期记忆 因为实现了RAG获取记忆,短期记忆的作用基本上也就局限于服务上下文了,可以使用滑动窗口的方法管理,限制在一定额度即可
吐槽 插一嘴,LLM的质量很大程度决定了上述回复的质量,与其质疑自己的代码,不如想想换个能读懂prompt的LLM
在做RAG之前我一直用的都是本地的Qwen3.5:2B,但是它读prompt的效率实在太低了,尤其是Tool和prompt越写越多的情况下,它经常抽风不听话,最终还是换成了qwen3.5-plus的API