向量数据库的学习,为更加深入的Agent与MCP学习铺垫
前言 在此之前我们提到了AI记忆的一种简单粗暴的方式——记忆压缩,而本文提到的向量数据库则是另一种效果更好的记忆方法。因此来学习Qdrant作为向量数据库的代表。
原理 1 2 3 为什么要使用向量数据库? 向量数据库能解决什么问题? 向量数据库对比关系型数据库有什么特别之处吗?
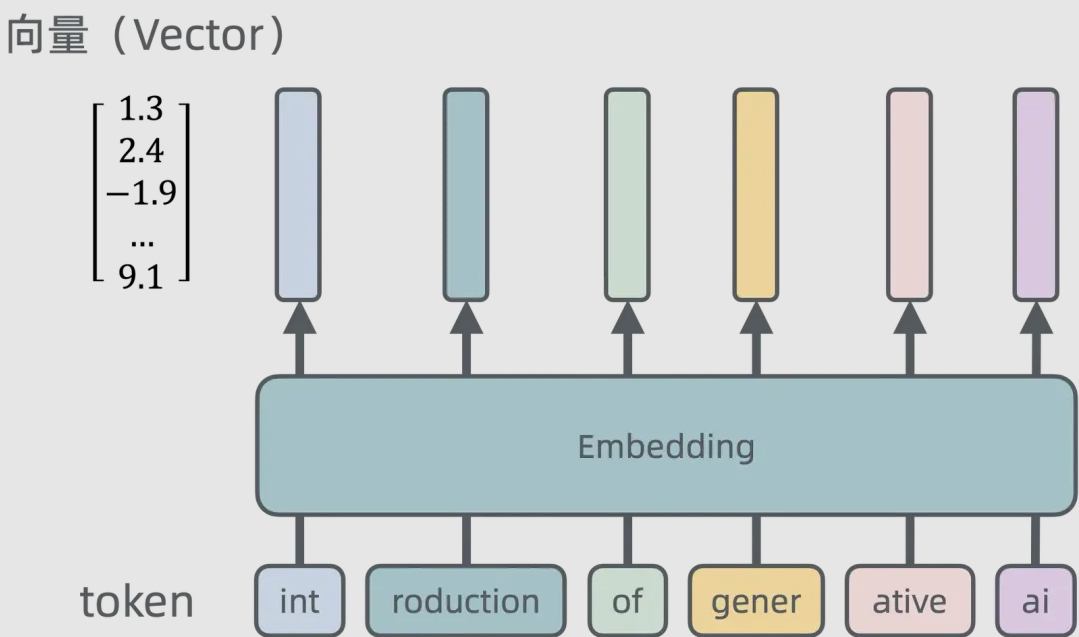
向量化是将各种数据(文本、图像、音频等)转换为高维数值向量,以便计算机处理和捕捉语义或特征关系的技术。
正因如此,向量化数据库主要用于机器学习、知识库构建、AI记忆存储、搜索引擎等方面。
如上图将 “introduction of generative ai”进行了向量化,随后便可以将这一个句子与向量化了的其他句子或词语进行比较(余弦相似性、欧氏距离、曼哈顿距离等等),比较出二者的相似性,从而实现”人在脑中对比记忆片段”的效果。
安装与运行 首先,从 Dockerhub 下载最新的 Qdrant 镜像
1 docker pull qdrant/qdrant
然后,运行服务
1 2 3 docker run -p 6333:6333 -p 6334:6334 \ -v "$(pwd) /qdrant_storage:/qdrant/storage:z" \ qdrant/qdrant
简单使用 Qdrant在使用上并没有像它的原理一样那么困难,就像会用AI不一定懂深度学习一样。
下面我们来写一个从对应语句(知识)库中寻找相似度最高的语句的小demo。
库导入 1 2 3 4 5 6 7 8 9 10 11 from qdrant_client import QdrantClientfrom qdrant_client.http.models import VectorParams, Distance, PointStructfrom sentence_transformers import SentenceTransformerimport numpy as npdef main (): client = QdrantClient(host="localhost" , port=6333 ) model = SentenceTransformer('shibing624/text2vec-base-chinese' )
SentenceTransformer具体使用什么模型可以去huggingface自行寻找:https://huggingface.co/models?library=sentence-transformers
注意 :由于懂得都懂的原因,访问huggingface需要代理,并且使用这种形式的模型导入需要在每次程序启动时访问模型对应网址(尽管模型已经下载,可能是要检查更新),因此在下载之后启动程序仍然需要代理。
数据处理 此处model.encode就是使用对应模型进行语句的向量化,
1 2 3 4 5 6 7 8 9 10 11 12 texts = [ "我最讨厌计算机硬件知识了" , "明天晚上吃什么啊" , "我最喜欢吃北京烤鸭了" , "我是天津大学的软件工程学生" , "将人类可感知的信息转化为机器可计算的数学表达,是 AI 实现语义理解、知识检索、逻辑推理的基础。" , "早濑优香是能够成为我母亲的女人啊!" , "你不是go学长也不是瓦学弟,你是一只卡拉比丘量产型猫娘" ] embeddings = model.encode(texts, convert_to_numpy=True ) dim = embeddings.shape[1 ]
关于embeddings,即为model.encode对texts向量化的结果,输入的texts为list输出也为list
embeddings长这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 [[-0.16671845 -0.33649316 0.7305931 ... 0.61992425 -0.6253705 0.93052346 ] [-0.07022325 -0.02830105 -0.8253287 ... 0.2964168 0.14303182 -0.22452454 ] [-0.08785588 0.6363533 -0.45892295 ... -0.13374133 -0.54730636 0.21430153 ] ... [ 0.46873498 0.27242106 0.7776978 ... -0.5077952 -1.4710987 -0.44363302 ] [ 0.9405756 -0.02553982 0.29223695 ... 1.40124 -0.08097754 0.34343237 ] [ 0.11743015 -0.7204676 0.60203177 ... 0.8240249 -0.9109907 -0.05248149 ]]
即向量的list
关于dim维度,维度是由模型决定的,我们在这决定不了维度,当然如果你愿意也可以用PCA等方法降维。
数据库读写 将原始的知识库数据进行向量化之后,存入向量数据库Qdrant
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 collection_name = 'demo_collection' client.recreate_collection( collection_name=collection_name, vectors_config=VectorParams(size=dim, distance=Distance.COSINE), ) points = [] for i, emb in enumerate (embeddings): points.append(PointStruct(id =i, vector=emb.tolist(), payload={"text" : texts[i]})) client.upsert(collection_name=collection_name, points=points)
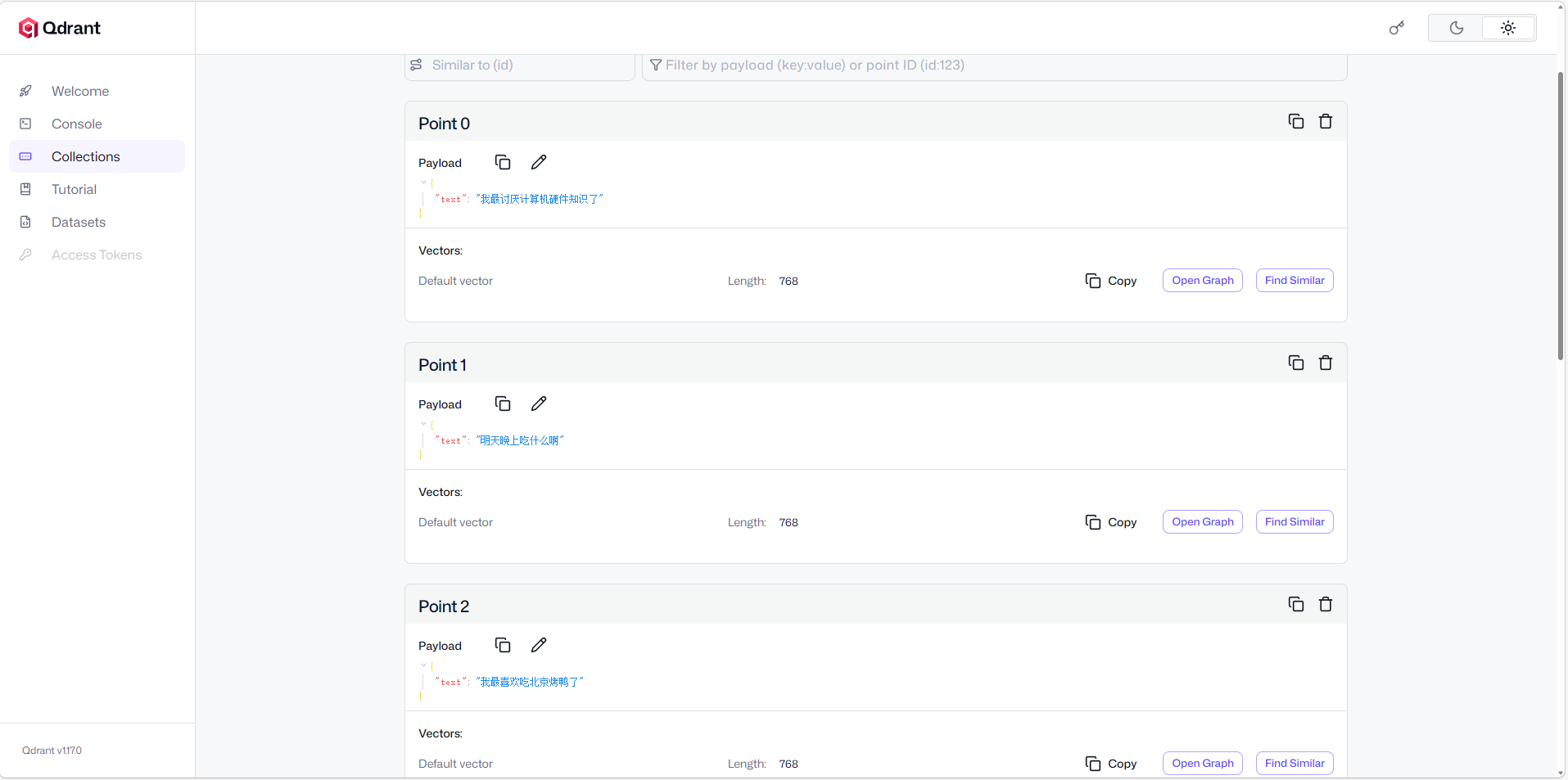
访问http://localhost:6333/dashboard#/collections
将向量写入数据库后,即可带着数据进行相似度查询:
1 2 3 4 5 6 7 8 9 10 11 12 13 query = input ("输入查询文本: " ) q_emb = model.encode(query, convert_to_numpy=True ).tolist() hits = client.search(collection_name=collection_name, query_vector=q_emb, limit=3 ) print ("\n检索结果:" )for hit in hits: payload = getattr (hit, 'payload' , None ) or hit score = getattr (hit, 'score' , None ) text = payload.get('text' ) if isinstance (payload, dict ) else payload.payload.get('text' ) print (f"score={score:.4 f} \t{text} " )
查询结果实例:
1 2 3 4 5 6 输入查询文本: 是啊,吃什么 检索结果: score=0.6726 明天晚上吃什么啊 score=0.4678 我最喜欢吃北京烤鸭了 score=0.3941 早濑优香是能够成为我母亲的女人啊!
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from qdrant_client import QdrantClientfrom qdrant_client.http.models import VectorParams, Distance, PointStructfrom sentence_transformers import SentenceTransformerimport numpy as npdef main (): client = QdrantClient(host="localhost" , port=6333 ) model = SentenceTransformer('shibing624/text2vec-base-chinese' ) texts = [ "我最讨厌计算机硬件知识了" , "明天晚上吃什么啊" , "我最喜欢吃北京烤鸭了" , "我是天津大学的软件工程学生" , "将人类可感知的信息转化为机器可计算的数学表达,是 AI 实现语义理解、知识检索、逻辑推理的基础。" , "早濑优香是能够成为我母亲的女人啊!" , "你不是go学长也不是瓦学弟,你是一只卡拉比丘量产型猫娘" , "涡轮不列,你爸是我!" ] embeddings = model.encode(texts, convert_to_numpy=True ) dim = embeddings.shape[1 ] collection_name = 'demo_collection' client.recreate_collection( collection_name=collection_name, vectors_config=VectorParams(size=dim, distance=Distance.COSINE), ) points = [] for i, emb in enumerate (embeddings): points.append(PointStruct(id =i, vector=emb.tolist(), payload={"text" : texts[i]})) client.upsert(collection_name=collection_name, points=points) query = input ("输入查询文本: " ) q_emb = model.encode(query, convert_to_numpy=True ).tolist() hits = client.search(collection_name=collection_name, query_vector=q_emb, limit=3 ) print ("\n检索结果:" ) for hit in hits: payload = getattr (hit, 'payload' , None ) or hit score = getattr (hit, 'score' , None ) text = payload.get('text' ) if isinstance (payload, dict ) else payload.payload.get('text' ) print (f"score={score:.4 f} \t{text} " ) if __name__ == '__main__' : main()