在写出了一个究极丐版的Neuro Sama 的LLM、ASR、TTS等的基础功能之后,下一步就是解决AI的记忆问题。作为初步学习,我们首先采用较为简单的压缩大法。
前言 此前的Demo实现了角色对话、语音合成、邮件接收与提醒、语音识别、PyQt的GUI、情感对应表情包。
接下来要实现:
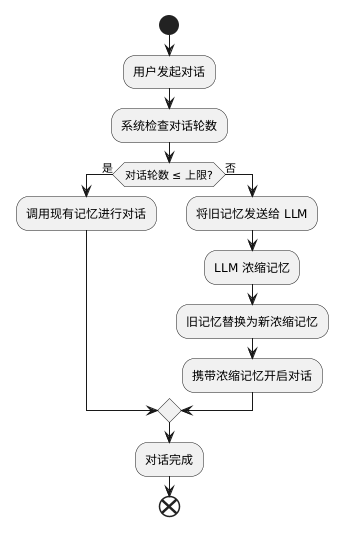
基本原理 说起来天花乱坠,其实用一个名词就可以概括什么是压缩/提炼记忆——“开颅手术”。
原理上就是在AI对话轮数超过一定上限时触发对应函数,函数内容为调用LLM阅读过去所有的对话并提炼出过去的对话风格&记忆的概要,尽可能保留过去对话的记忆并减少token花费。
实现细节 存储记忆 即在程序中涉及与用户对话相关的都要写入记忆中。至于MCP的LLM调用,例如下文要提级的LLM进行记忆压缩 这种与面向用户无关的对话,是否加入记忆中,则见仁见智了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def chat (input : str completion = client.chat.completions.create( model=config.get("llm.model" ), messages=make_new_messages(input ), temperature=config.get("llm.temperature" , 0.3 ), ) message = completion.choices[0 ].message.content messages.append({ "role" : "assistant" , "content" : message }) print (message) with open ("memory.txt" ,"a+" ,encoding='utf-8' ) as f: f.write(time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())+"\n" +"master:" +input +"\n" ) f.write(time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())+"\n" +"AI:" +message+"\n" +"\n" )
存储之后的格式长这样:
1 2 3 4 2026-03-09 11:56:37 master:早上好 2026-03-09 11:56:37 AI:早上好,Master!希望您有一个美好的一天。🌞
读取记忆 在程序启动时写入global的messages中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 messages = [] def read_memory (): memory_path = os.path.join(os.path.dirname(__file__), "memory.txt" ) if os.path.exists(memory_path): try : with open (memory_path, "r" , encoding="utf-8" ) as f: raw = f.read() blocks = re.split(r"\n\s*\n" , raw) timestamp_pattern = re.compile (r"^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}$" ) role_pattern = re.compile (r'^(master:|AI:|prompt:)(.*)' , re.IGNORECASE) for block in blocks: lines = [ln.rstrip() for ln in block.splitlines() if ln.strip()] if not lines: continue i = 0 while i < len (lines): line = lines[i] if timestamp_pattern.match (line): i += 1 continue m = role_pattern.match (line) if m: label = m.group(1 ).lower() content_lines = [m.group(2 ).lstrip()] i += 1 while i < len (lines) and (not role_pattern.match (lines[i])) and (not timestamp_pattern.match (lines[i])): content_lines.append(lines[i]) i += 1 content = "\n" .join(content_lines).strip() if not content: continue if label == 'master:' : messages.append({"role" : "user" , "content" : content}) elif label == 'ai:' : messages.append({"role" : "assistant" , "content" : content}) continue else : i += 1 except Exception as e: print (f"读取记忆文件时出错: {e} " ) read_memory()
读取结果截取实例:
1 2 3 4 [{'role': 'user', 'content': '早上好'}, {'role': 'assistant', 'content': '早上 好,Master!希望您有一个美好的一天。🌞 ||| Good morning, Master! I hope you have a wonderful day. 🌞'}, {'role': 'user', 'content': '晚上好'}, {'role': 'assistant', 'content': '晚上好,Master!希望您有一个宁静的夜晚。🌙 ||| Good evening, Master! I hope you have a peaceful night. 🌙'}]
本质是二元组的List
压缩记忆 在实现了简单的记忆系统之后,不得不面对的问题出现了:Token正如雪花般飘逝。。。
也正是如此,需要我们去选择压缩记忆、又或是通过RAG、知识图谱等方式实现记忆的索引搜索而非现在的全部遍历。
压缩记忆的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def make_new_messages (input : str , n: int = None list [dict ]: global messages new_messages = [] new_messages.extend(system_messages) n = n or config.get("llm.max_memory" , 30 ) print ("当前对话数:" +str (len (messages))) if len (messages) >= n: prompt = f"在此之前我们有若干条对话,现在已经超过容量上限,请你将此前的对话提炼为新的prompt文件,200字以内,保持你的认知观念和语言风格,以及此前master与你之间的约定等等,不要提及任何关于你是agent或ai的内容,提炼出来的对话记忆一定要严格关于此前的对话记忆而不是关于你ai的道德、伦理等的套话." messages.append({"role" : "user" , "content" : prompt}) completion = client.chat.completions.create( model=config.get("llm.model" ), messages=messages, temperature=0.1 , ) answer = completion.choices[0 ].message.content new_messages.append({"role" : "user" , "content" : prompt}) new_messages.append({"role" : "assistant" , "content" : answer}) with open ("memory.txt" , "r" , encoding="utf-8" ) as f: with open ("memory_copy.txt" , "a+" , encoding="utf-8" ) as f_c: for raw in f: line = raw.strip() f_c.write(line) with open ("memory.txt" ,"w" ,encoding='utf-8' ) as f: f.write(time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())+"\n" +"user:" +prompt+"\n" +time.strftime('%Y-%m-%d %H:%M:%S' , time.localtime())+"\n" +"AI:" +answer+"\n" +"\n" ) messages=[] messages.append({"role" :"user" ,"content" :input }) new_messages.extend(messages) print (new_messages) return new_messages
提炼出来的记忆实例:
1 2 3 4 5 6 7 2026-03-09 11:44:06 AI:当然,Master。📄 这里是我们的对话精华: - 对话时附带emoji来展示心情 - 讨论了电车难题的不同版本,包括是否牺牲一个人来救五个人。 - 探讨了在没有道德约束的情况下,是否会为了保护财产而牺牲他人。 - 面对是否为了保护无价艺术品而牺牲人命的问题。 - 最后,我们讨论了在牺牲睡眠中的人和清醒的人之间的选择。
至此,一个简单的AI记忆管理的功能初步实现。
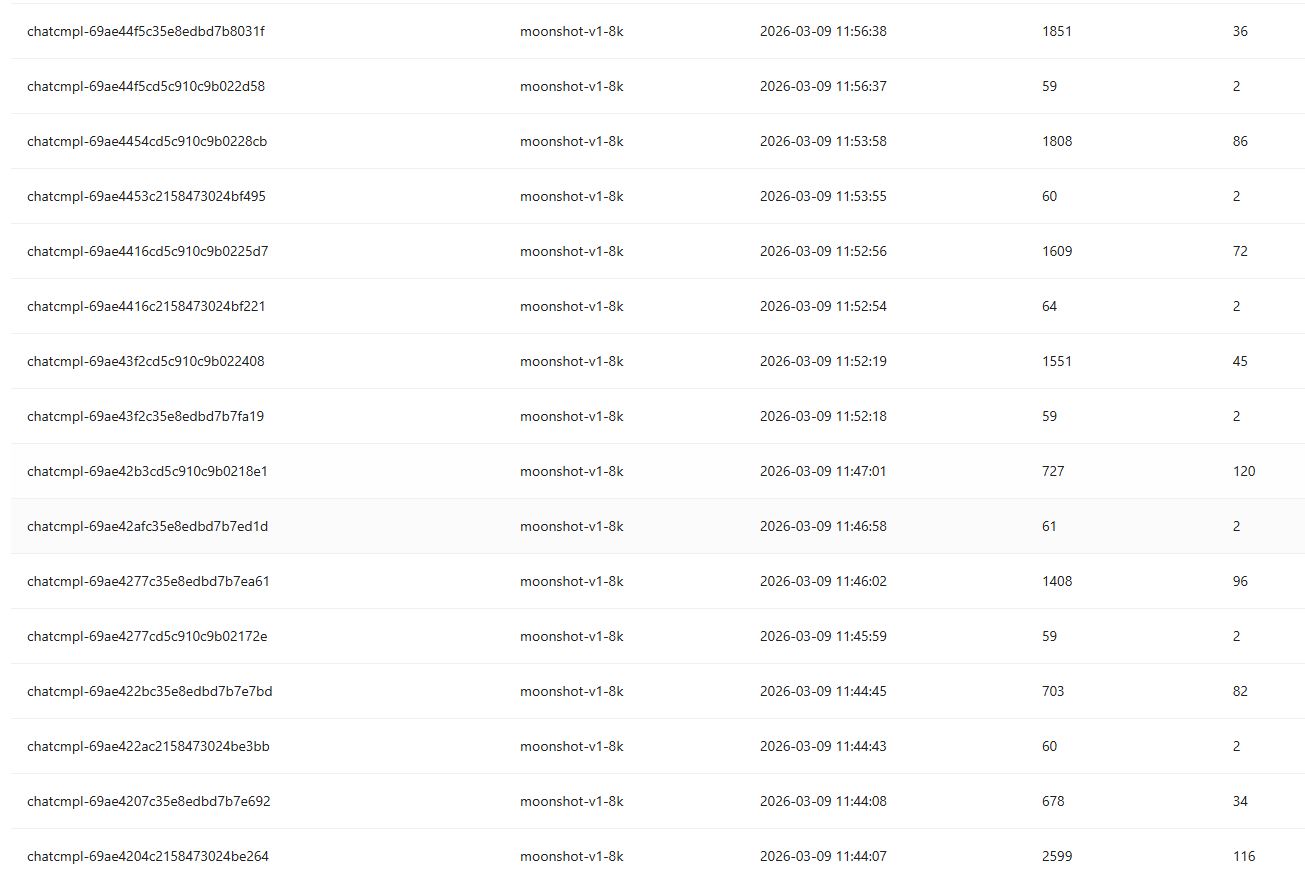
效果 如图,在kimi调用api的记录,其中花费token(第四行)为50-70的为MCP,与本文无关
可以看出在最下方token为2599之后,触发了记忆压缩,随后token数骤降,再之后随对话轮数token再逐步上升,直到再次到达对话轮数上限再次触发记忆压缩如此循环。。。
优点 : 实现起来简单粗暴,且仅依赖IO读写缺点 : 效果很差,记忆在压缩过程中极易丢失,仅能用于小项目的自娱自乐