对此前demo的完善,仍旧处于初期的开发
前言
此前的Demo实现了角色对话、语音合成、邮件接收与提醒。
接下来要实现:
1.语音识别(用户对话)
2.GUI
3.情感对应的对话表情包 以及 TTS的情感体现
语音录制
通过语音识别让用户实现语音输入与AI交互。
但是现在已经不仅仅是语音识别了,我们现在要实现用户的语音输入,即录音功能。
使用pyaudio与wave库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
is_recording = 0
def record_audio(wave_out_path, record_second):
global is_recording
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录制")
is_recording=1
wf = wave.open(wave_out_path, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
for _ in range(0, int(RATE * record_second / CHUNK)):
data = stream.read(CHUNK)
wf.writeframes(data)
if is_recording==0:
print("录音打断")
break
stream.stop_stream()
stream.close()
print("完成录制")
is_recording=0
p.terminate()
wf.close()
|
按钮信号与槽
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def handle_audio(self):
if audio_record.is_recording == 0:
"""用户按下按钮开始录音,并自动发送"""
self.ui.audioButton.setText("停止录音")
self.record_thread = threading.Thread(
target=self._record_and_process,
daemon=True
)
self.record_thread.start()
elif audio_record.is_recording == 1:
self.ui.audioButton.setText("开始录音")
audio_record.is_recording = 0
|
语音识别
借助了 FunAsr ,参见我此前的博客
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| model = AutoModel(
model="paraformer-zh",
vad_model="fsmn-vad",
punc_model="ct-punc-c",
spk_model="cam++",
disable_update=True
)
def audio_to_text():
res = model.generate(
input="C:\\Users\\X.J\\Desktop\\live2d_ai\\gui\\record.wav",
batch_size_s=60,
)
print(res)
return res
|
录音并提取文本提交给ai
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def _record_and_process(self):
audio_record.record_audio("record.wav", 20)
if audio_record.is_recording == 0:
user_input = asr.audio_to_text()[0].get("text","")
print("用户输入"+user_input)
if user_input:
self.update_ui_signal.emit("你", user_input, True)
response = llm.chat(user_input)
self.update_ui_signal.emit("AI", response, False)
live2d_api.send_json_message(response)
live2d_api.send_sound()
if not user_input:
self.update_ui_signal.emit("AI", "未识别到语音内容,请重试", False)
return
|
GUI
那么就写一个UI吧,由于代码都是python完成的,所以想到了使用pyQt去写UI
这里使用PySide6
初期UI,懒得美化

表情包与对话情感(???)
并非真正的情感,而是让llm在每次返回句子的时候选择一个展示给用户的表情。关于如何催眠llm这样做就不赘述了,和角色提示词的思路差不多。
该表情用中文中括号包围 :
例如: 你好【微笑】
在接收到句子后通过字符串操作提取出纯净句子(pure_text)与表情(expression)
pure_text依旧用于展示在页面中给用户,expression有着对应的文件夹下存储所有可能的表情,并直接写入html。
资源来自 蔚蓝档案wiki ,差分就是好啊(赞赏)!
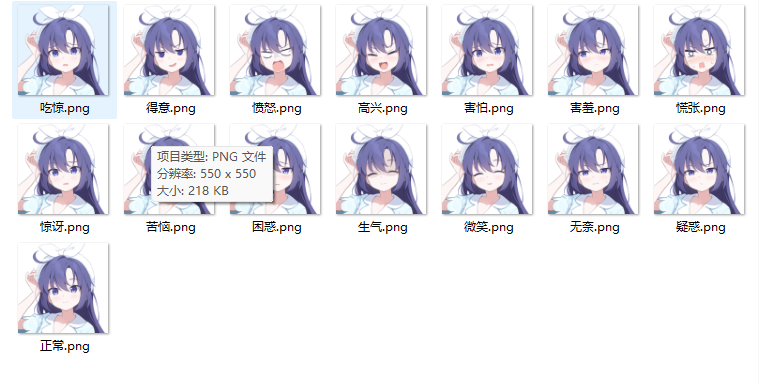
提取pure_text与expression
1
2
3
4
5
6
7
|
pattern = r'【[^】]*】'
pure_text = re.sub(pattern, '', response)
if pure_text != response:
expression = response.split("【")[1][:2]
print("表情"+expression)
self.add_message_to_display("AI", pure_text,expression ,False)
|
调用,并将img插入html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| def add_message_to_display(self, sender: str, content: str, expression: str , is_user: bool):
"""添加消息到聊天区域"""
escaped_content = html.escape(content).replace('\n', '<br>')
from datetime import datetime
timestamp = datetime.now().strftime("%H:%M")
if is_user:
"""省略"""
else:
message_html = f'''
<table width="100%" cellpadding="0" cellspacing="0">
<tr>
<td width="70%" align="left">
<div style="background: #FF0; color: #000; padding: 10px 15px;
border-radius: 18px; border-bottom-left-radius: 5px;
border: 1px solid #E5E5EA; max-width: 100%;">
<strong>{sender}</strong><br>{escaped_content}
</div>
<div style="font-size: 11px; color: #999; margin: 5px 8px;">
{timestamp}
</div>
</td>
<td width="30%"></td>
</tr>
</table>
<img style="width:20%; height:auto; max-width:160px; display:block; margin-top:130px;" src="expressions/{expression}.png">
'''
|
最终效果如下:

只是看起来还是非常有内味的,只是不知道为什么像重做个类MomoTalk的UI了。(Flag)