Redis经典问题之缓存穿透的两种解决方法
缓存穿透
这里开始就有些进阶了。
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
也就是说需要Redis作为主数据库的”拦截器”,利用其基于内存的高性能特性,去应对大规模的请求(尤其是恶意的空请求)。
解决方法:缓存空对象、布隆过滤器
缓存空对象
在数据库查询为空后(第一次对数据库的访问不可避免),向Redis写入对应Key的空值,此后该访问就会访问到Redis。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Override
public Orders getOrdersById(Integer orderId) {
String key = "orders:id:" + orderId;
Orders redis_order = (Orders) redisTemplate.opsForValue().get(key);
if(redis_order != null)
return redis_order;
Orders orders =ordersMapper.getOrdersById(orderId);
if(orders == null){
Orders empty_order = new Orders();
empty_order.setId(-1);
redisTemplate.opsForValue().set(key,empty_order,600, TimeUnit.SECONDS);
return null;
}
redisTemplate.opsForValue().set(key,orders,3600, TimeUnit.SECONDS);
return orders;
}
|
但是缓存空对象本质上是防君子不防小人的保护策略,它仅仅是解决了一些无心之举的重复访问。
前面提到,缓存空对象对数据库的第一次访问不可避免,那么如果有心之人访问一次换一个Key:id,那么就会不停访问数据库,并且还会不断让你向Redis写入缓存的空数据去污染你的缓存!
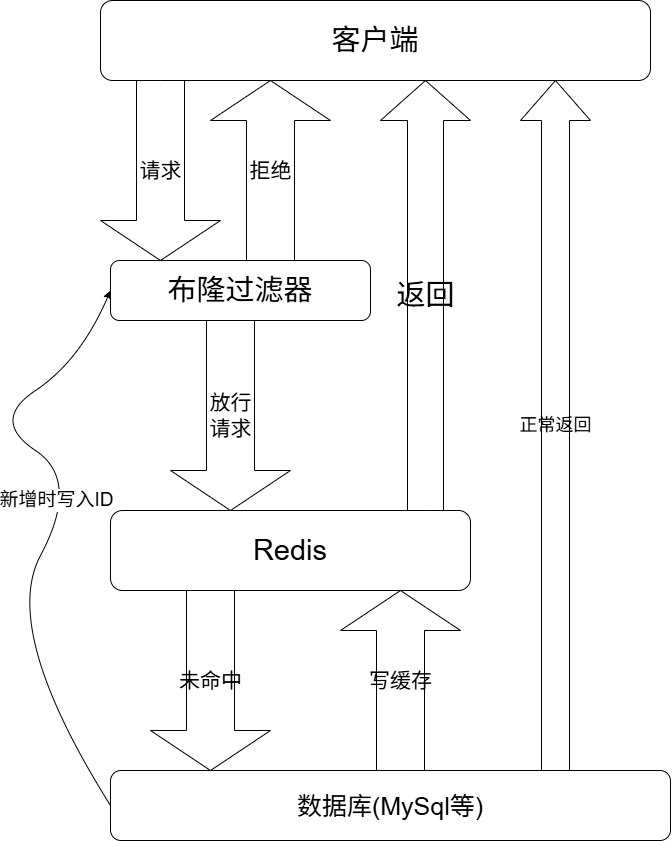
布隆过滤器
再次新增一条过滤,在项目启动时访问所有有效的Id(Key),存入布隆过滤器,客户端访问Key时先经过布隆过滤器,如果该Key不存在有效Value,则直接拒绝访问,如果存在,则走正常流程。 项目运行期间数据库新增数据时也要同时将对应的Key写入布隆过滤器。
引入布隆过滤器依赖
1
2
3
4
5
| <dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
|
创建布隆过滤器配置类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.nio.charset.StandardCharsets;
@Configuration
public class BloomFilterConfig {
private static final int EXPECTED_INSERTIONS = 1000000;
private static final double FPP = 0.01;
@Bean
public BloomFilter<Integer> orderIdBloomFilter() {
return BloomFilter.create(
Funnels.integerFunnel(),
EXPECTED_INSERTIONS,
FPP
);
}
}
|
初始化布隆过滤器数据
在项目启动时向数据库发起getAllOrderIds,从而让布隆过滤器获取已有的Key:id
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| package com.elm.util;
import com.google.common.hash.BloomFilter;
import com.elm.mapper.OrdersMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
@Component
public class BloomFilterInitializer implements CommandLineRunner {
@Autowired
private OrdersMapper ordersMapper;
@Autowired
private BloomFilter<Integer> orderIdBloomFilter;
@Override
public void run(String... args) throws Exception {
List<Integer> allOrderIds = ordersMapper.getAllOrderIds();
for (Integer orderId : allOrderIds) {
orderIdBloomFilter.put(orderId);
}
System.out.println("布隆过滤器初始化完成,加载订单ID数量:" + allOrderIds.size());
}
}
|
在业务层使用布隆过滤器
先通过布隆过滤器判断是否存在,存在则进入下一步寻找缓存,不存在则直接throw
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| @Override
public Orders getOrdersById(Integer orderId) {
if (orderId == null || !orderIdBloomFilter.mightContain(orderId)) {
System.out.println("布隆过滤器判断订单ID不存在,避免缓存穿透");
throw new RuntimeException("订单ID不存在");
}
String key = "orders:id:" + orderId;
Orders redis_order = (Orders) redisTemplate.opsForValue().get(key);
if (redis_order != null) {
System.out.println("缓存命中");
return redis_order;
}
User user = userMapper.getUserByName(getCurrentUserName());
Orders orders = ordersMapper.getOrdersById(orderId);
if (orders == null) {
Orders empty_order = new Orders();
empty_order.setId(-1);
redisTemplate.opsForValue().set(key, empty_order, 600, TimeUnit.SECONDS);
return null;
}
redisTemplate.opsForValue().set(key, orders, 3600, TimeUnit.SECONDS);
return orders;
}
|
维护布隆过滤器数据
在createOrders方法中加入这一条,即新建Order时也要向布隆过滤器新增Key:id保持同步
1
2
|
orderIdBloomFilter.put(order.getId());
|
测试
输入不存在id时,布隆过滤器成功拦截
1
2
3
4
5
6
| {
"success": false,
"code": "400",
"data": null,
"message": "订单ID不存在"
}
|