编译原理与技术lab2
编译原理与技术 实验2
目的和要求
目的:掌握Lex源代码的编写;按照给定词法规则,编写Lex代码,并编译生成对应词法分析器,识别出单词符号作为输出,发现其中的词法错误。
要求:(1)从键盘上/文件中输入源程序;(2)处理每个单词,计算单词的值和种别;(3)输出单词值和种别。
实验步骤
运行code/example/目录下的示例代码
在路径下依次输入
1 | flex lex.l |
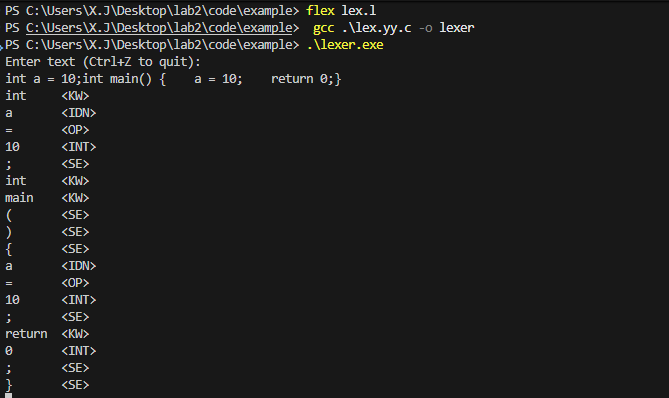
可见输入对应的程序代码后词法分析器正常运作
根据以下给定的词法规则和输出格式,编写Lex代码,生成词法分析器
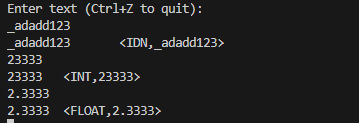
IDN,INT,FLOAT
最简单的三个,写好正则表达式即可
1 | ([a-zA-Z]|_)([a-zA-Z]|[0-9]|_)* { printf("%s\t<IDN,%s>\n", yytext,yytext); } |
自行测试如下
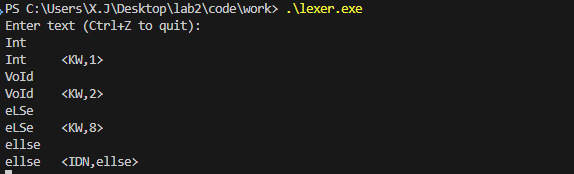
KW
这部分相对原来的样例代码多了两个问题:如何确定对应的text对应哪个数字标识? 如何匹配大小写的区分?
第一个问题:如何确定对应的text对应哪个数字标识。由于数据量较少,我们直接写在了输出里,其实可以开一个数组一一对应text与数字的关系。
第二个问题:如何匹配大小写的区分,将单词拆分为正则表达式的或操作,覆盖所有可能的大小写形式,其实也可以写一个将所有输入转换为小写形式的函数,转换之后再进行操作。
1 | [iI][nN][tT] { printf("%s\t<KW,%d>\n", yytext, 1); } |
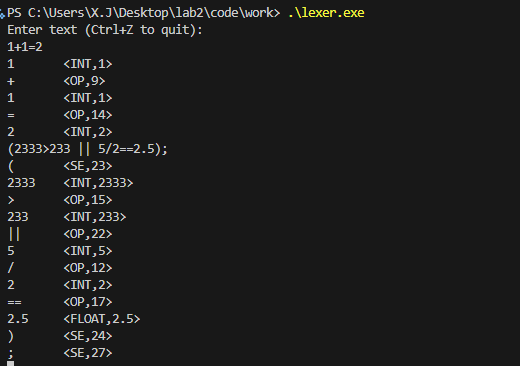
OP,SE
转换一下输出格式即可
1 | "+" { printf("%s\t<OP,%d>\n", yytext, 9); } |
ERROR
唯一的一个棘手的问题,我该如何知道当前出错符号的行和列呢?
维护一个行与列的变量,
让每一次读取之后都给行加上对应的text的length,读取空格加1,读取换行列加1,行置为0。
直接贴出完整代码
1 | %{ |
重点在于每次操作后col加上yyleng,以及对换行和空格的处理。
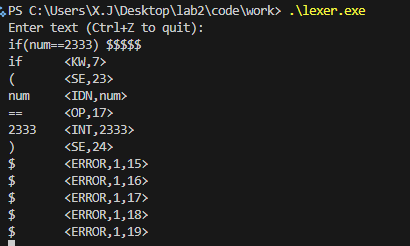
自行构造测试用例(包括正确程序和错误程序),输出对应符号表
在此之前,我们重写main函数,使其能够在命令行直接使用其他文件进行测试
1 | int main(int argc, char *argv[]) { |
test1:正确程序
原程序
1 | int main() { |
测试结果
1 | PS C:\Users\X.J\Desktop\lab2\code\work> ./lexer test1.cmm |
test2:错误程序
原程序:
1 | int main() { |
测试结果
1 | PS C:\Users\X.J\Desktop\lab2\code\work> ./lexer test2.cmm |
运行code/test/目录下的测试用例,检查通过情况
test1:
1 | PS C:\Users\X.J\Desktop\lab2\code\work> ./lexer ../test/test1.sy |
test2:
1 | PS C:\Users\X.J\Desktop\lab2\code\work> ./lexer ../test/test2.sy |
test3:
1 | PS C:\Users\X.J\Desktop\lab2\code\work> ./lexer ../test/test3.sy |